Redis
初识Redis
NoSQL
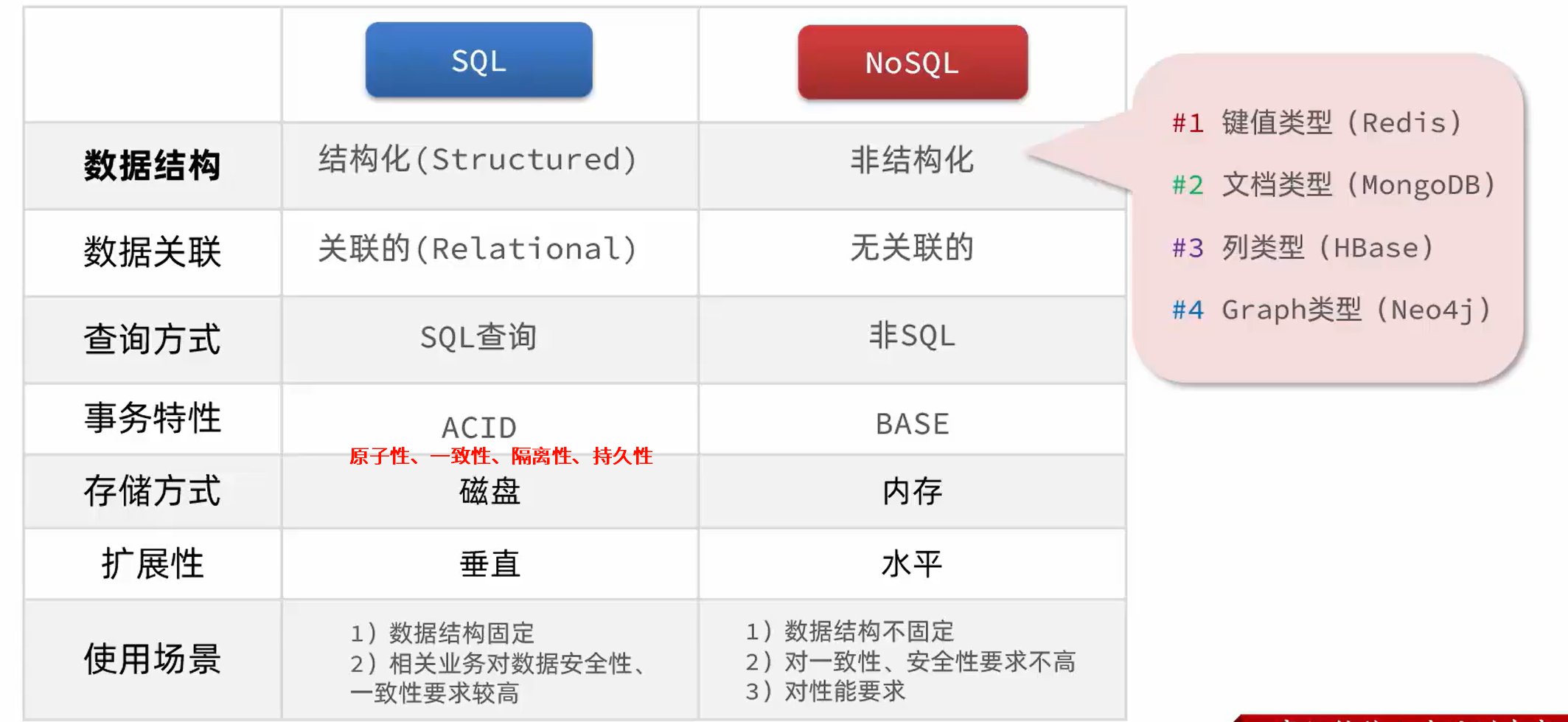
SQL用于持久存储的数据,NoSQL一般用作缓存。
Redis介绍

关于数据持久化:Redis支持一段时间后将内存中的数据迁移到磁盘中,使数据能够断电不消失。
Redis命令
Redis数据结构

通用命令
- KEYS:查看符合模板的所有key,不建议在生产环境设备上使用,效率很低(会阻塞所有的请求)
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
可通过help [command] 可以查看一个命令的具体用法
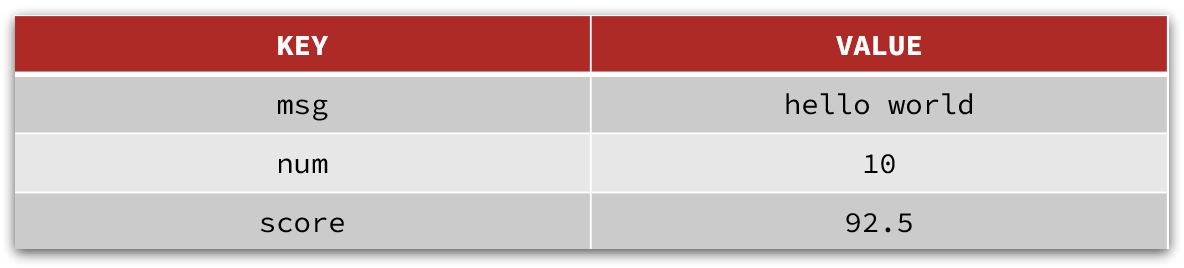
String类型
是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同(数字会转换成二进制存储)。字符串类型的最大空间不能超过512m
常见命令
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
Key结构
多个单词形成层级结构,单词之间用’:’隔开,格式如下:
1 | 项目名:业务名:类型:id |
这个格式并非固定,也可以根据自己的需求来删除或添加词条。这样以来,我们就可以把不同类型的数据区分开了。从而避免了key的冲突问题。
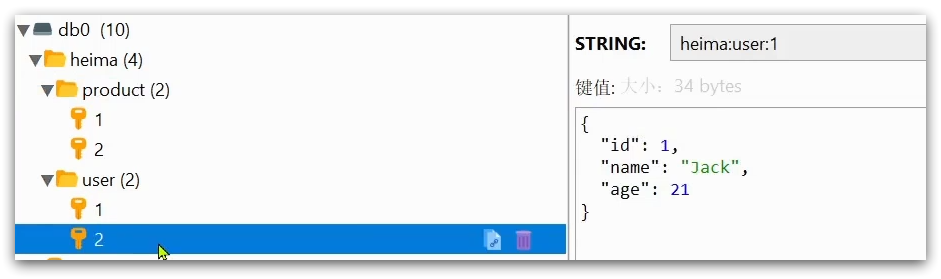
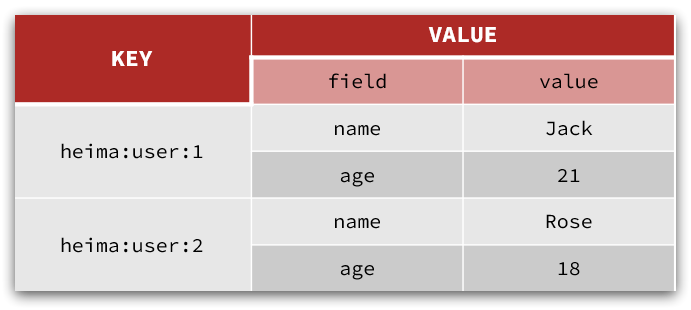
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
user相关的key:heima:user:1
product相关的key:heima:product:1
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {“id”:1, “name”: “Jack”, “age”: 21} |
| heima:product:1 | {“id”:1, “name”: “小米11”, “price”: 4999} |
并且,在Redis的桌面客户端中,还会以相同前缀作为层级结构,让数据看起来层次分明,关系清晰:
Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
Hash的常见命令有:
HSET key field value:添加或者修改hash类型key的field的值
HGET key field:获取一个hash类型key的field的值
HMSET:批量添加多个hash类型key的field的值(redis4.0后被启用,建议使用HSET)
HMGET:批量获取多个hash类型key的field的值
HGETALL:获取一个hash类型的key中的所有的field和value
HKEYS:获取一个hash类型的key中的所有的field
HINCRBY:让一个hash类型key的字段值自增并指定步长
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。

List的常见命令有:
- LPUSH key element … :向列表左侧插入一个或多个元素
- LPOP key number:移除并返回列表左侧的n个元素,没有则返回nil
- RPUSH key element … :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key start end:返回一段角标范围内的所有元素
- BLPOP key number time和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
无序
元素不可重复
查找快
支持交集、并集、差集等功能
Set的常见命令有:
- SADD key member … :向set中添加一个或多个元素
- SREM key member … : 移除set中的指定元素
- SCARD key: 返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
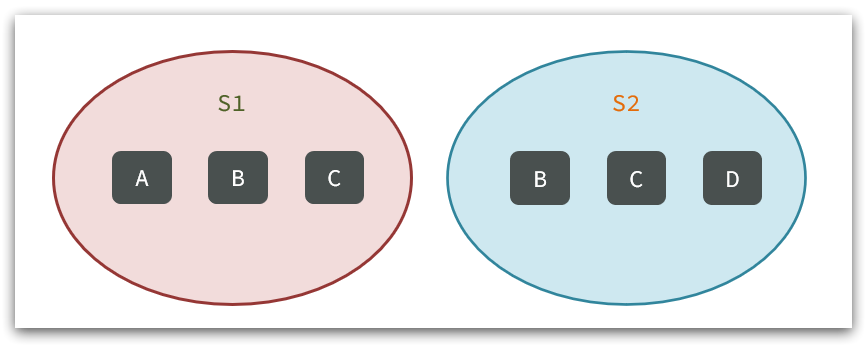
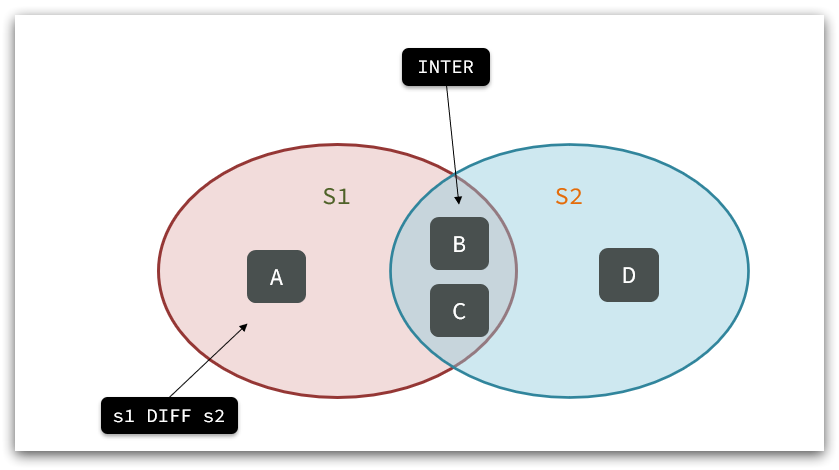
- SINTER key1 key2 … :求key1与key2的交集
例如两个集合:s1和s2:
求交集:SINTER s1 s2
求s1与s2的不同:SDIFF s1 s2
SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
升序获取sorted set 中的指定元素的排名:ZRANK key member
降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
Redis的Java客户端
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/

其中Java客户端也包含很多:
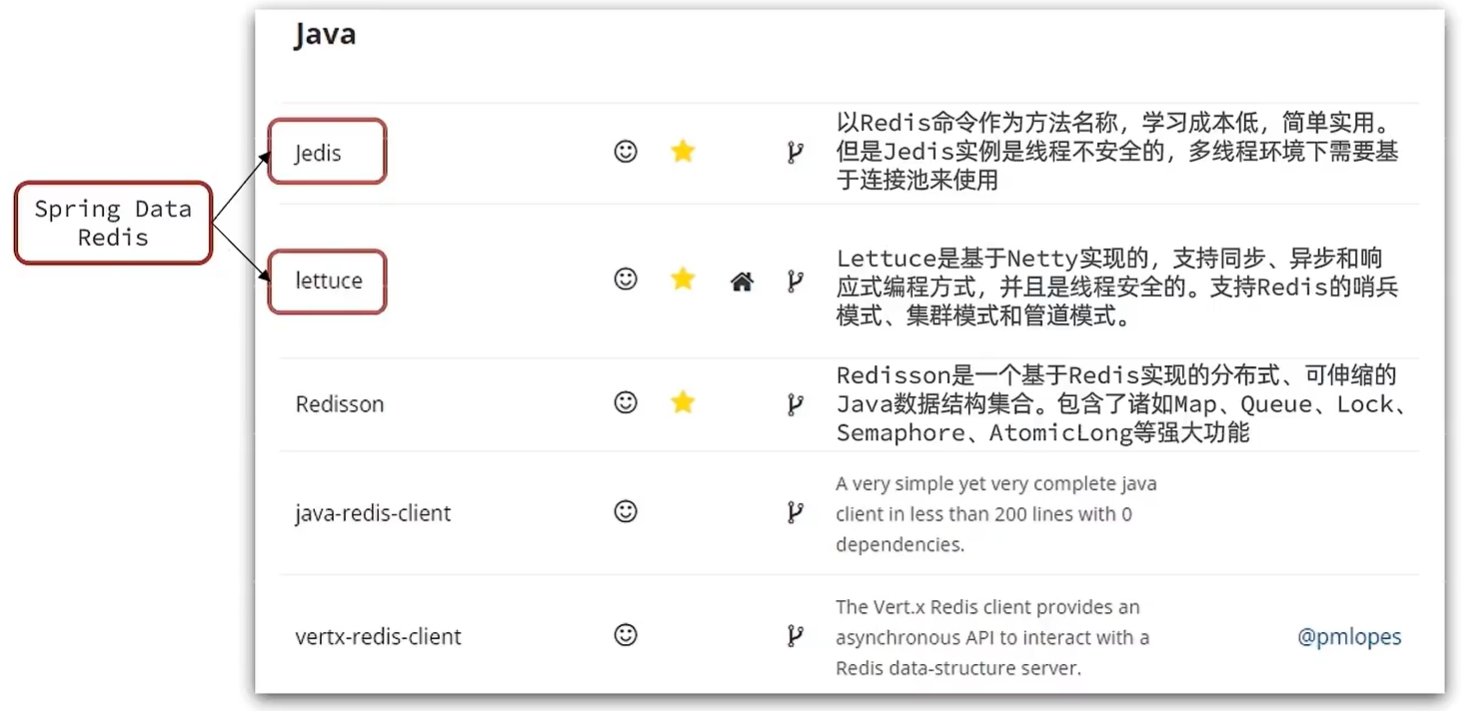
标记为💗的就是推荐使用的java客户端,包括:
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。Jedis线程不安全,多线程环境下需要配合连接池使用。Lettuce线程安全。
- Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。
Jedis客户端
Jedis的官网地址: https://github.com/redis/jedis
快速入门
我们先来个快速入门:
1)引入依赖:
1 | <!--jedis--> |
2)建立连接
新建一个单元测试类,内容如下:
1 | private Jedis jedis; |
3)测试:
1 |
|
4)释放资源
1 |
|
连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
1 | package com.heima.jedis.util; |
SpringDataRedis客户端
对jedis和lettuce进行了抽象和封装。
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

快速入门
SpringBoot已经提供了对SpringDataRedis的支持,使用非常简单。
首先,新建一个maven项目,然后按照下面步骤执行:
引入依赖
1 |
|
配置Redis
在application.yml中配置
1 | spring: |
注入RedisTemplate
因为有了SpringBoot的自动装配,我们可以拿来就用:
1 |
|
编写测试
1 |
|
自动序列化
RedisTemplate可以接收任意Object作为值写入Redis:
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
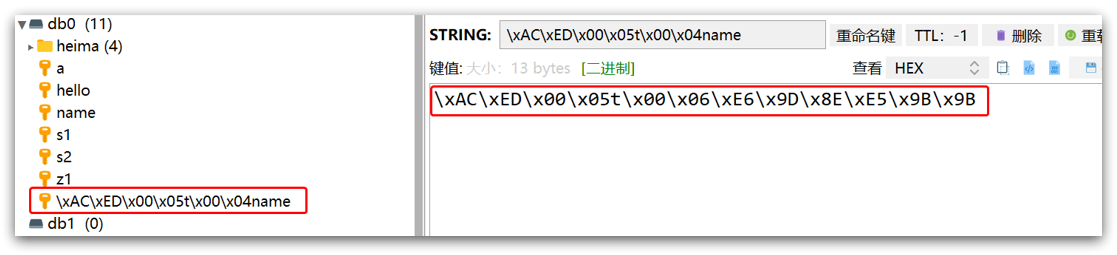
缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
1 |
|
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:
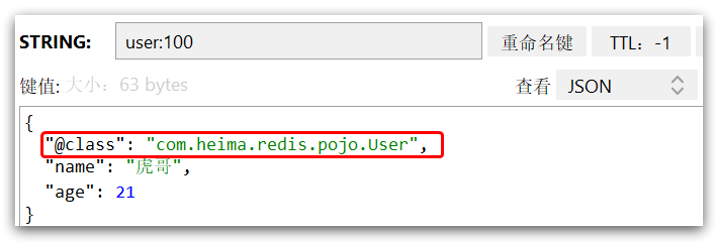
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
手动序列化 StringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
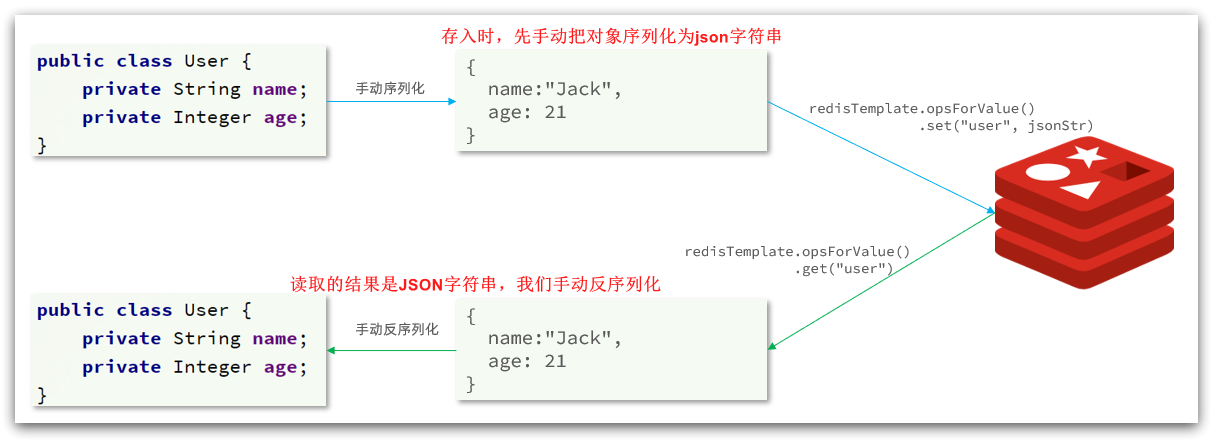
因为存入和读取时的序列化及反序列化都是我们自己实现的,SpringDataRedis就不会将class信息写入Redis了。
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
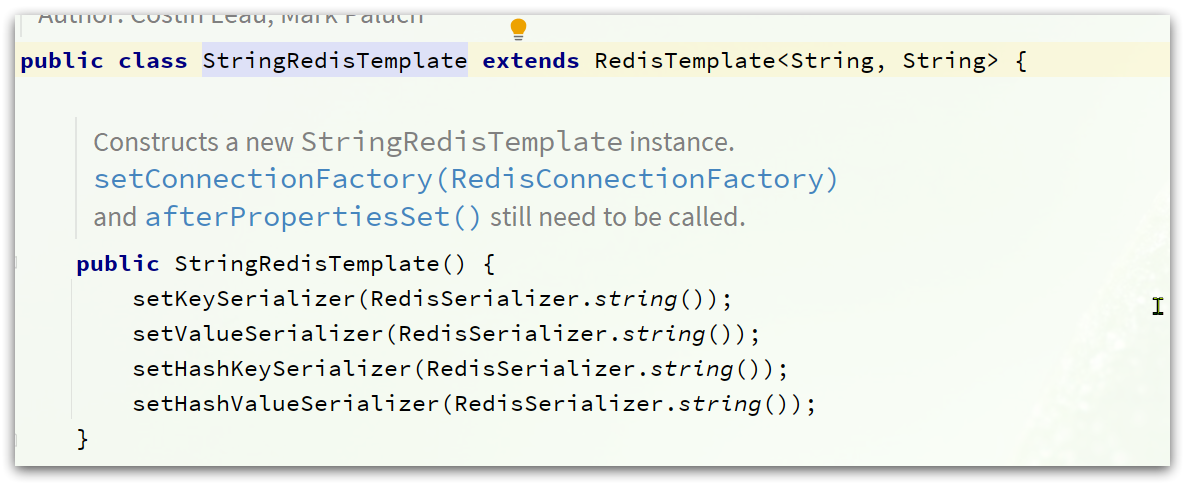
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
1 |
|
MVC 模式
Model-View-Controller(模型-视图-控制器) 模式。
- 模型(Model):负责数据和业务逻辑,通常包含数据存储、检索和业务规则。
- 视图(View):负责显示数据(模型)的用户界面,不包含业务逻辑。
- 控制器(Controller):接收用户的输入,调用模型和视图去完成用户的请求。
与三层架构模式的区别:
三层架构是基于业务逻辑来分的,而MVC是基于页面来分的
实战——黑马点评
发送验证码
1、如果需要在log中使用{}来表示变量,需要使用@Slf4j注解
2、controller中接收到手机号后,立刻调用service接口中实现的函数。这样可以通过接口代码文件快速看出这个接口有哪些函数,可以干什么。
验证码登录/注册
登录校验拦截器
1、拦截器要去实现 HandlerInterceptor接口
preHandle、postHandle、afterCompletion:
https://blog.csdn.net/qq_34246965/article/details/122943699
2、由于User中包含密码、手机号等敏感信息,如果直接把User存到session中,会导致敏感信息泄露。因此在存放到session时,需要将其转为UerDTO类型(仅包含部分信息)
使用BeanUtil的一个工具类copyProperties:
1 | session.setAttribute("user", BeanUtil.copyProperties(user, UserDTO.class)); |
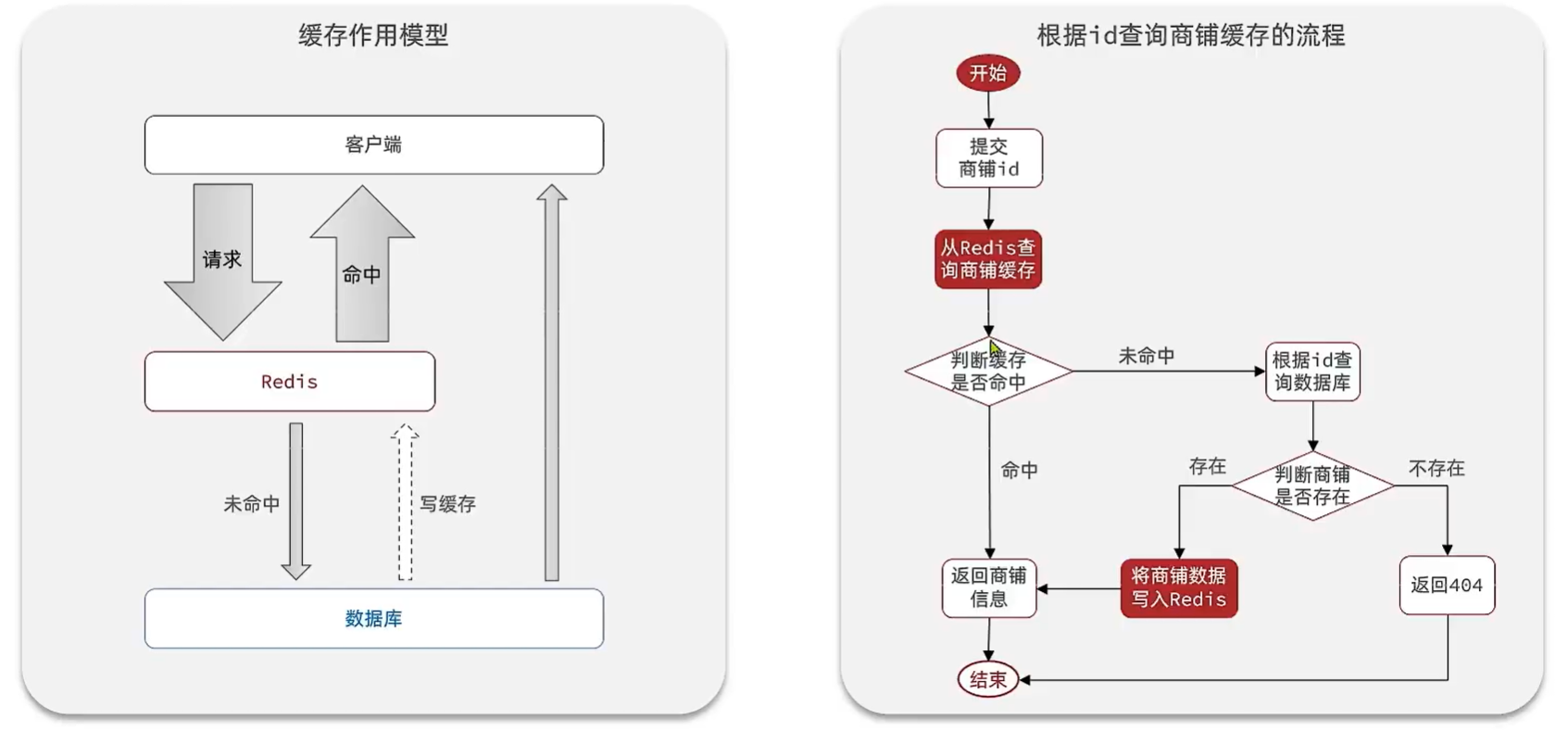
缓存
流程
更新策略
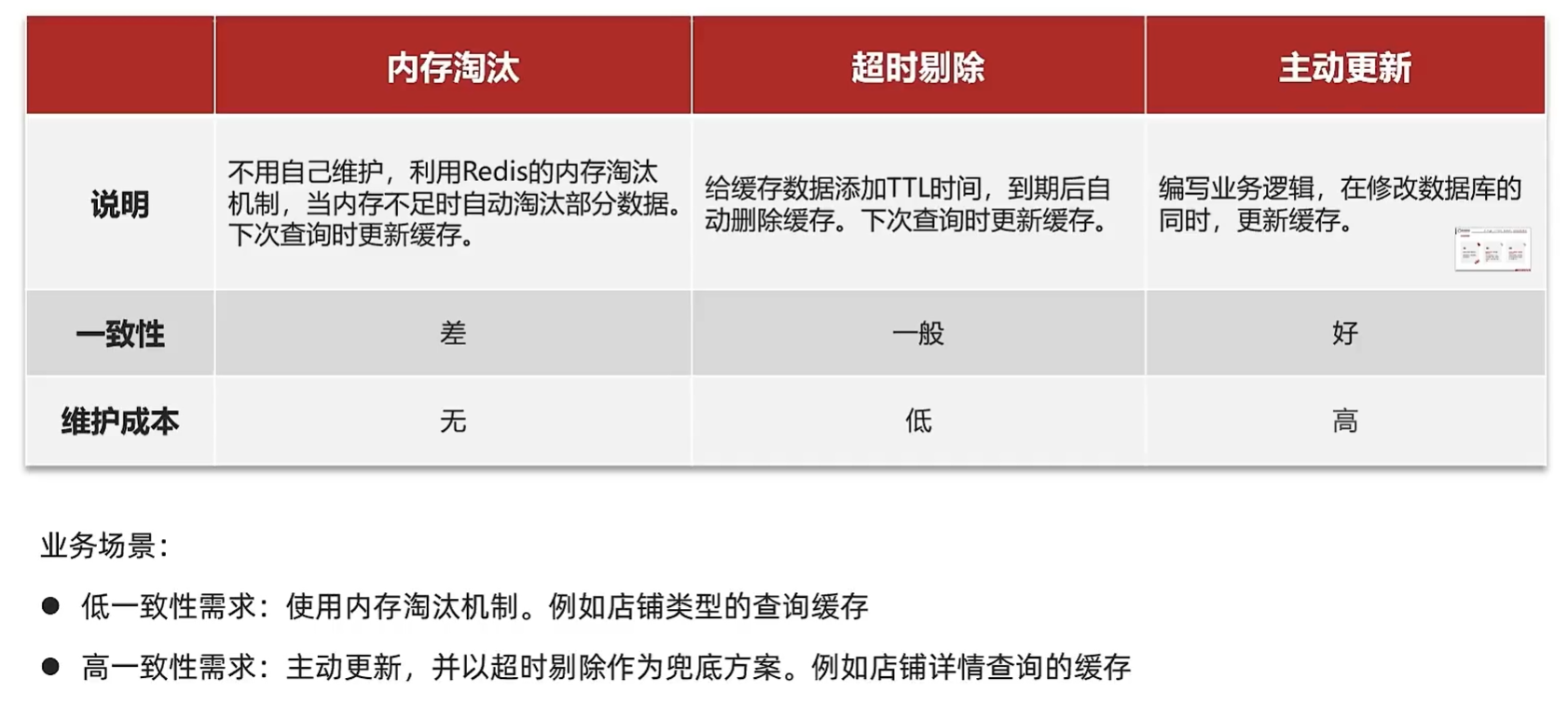
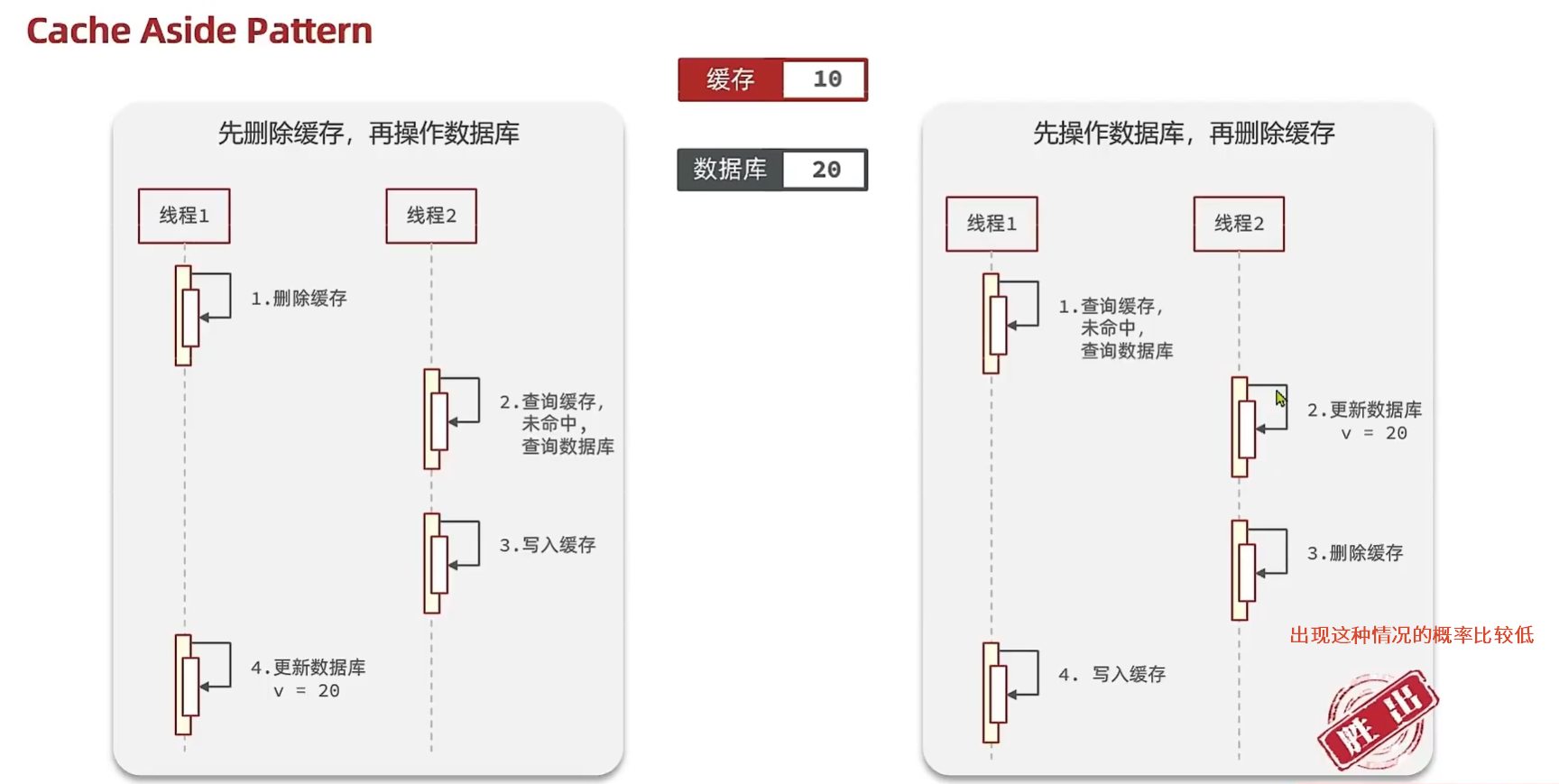
主动更新策略

优惠券秒杀
1、全局ID
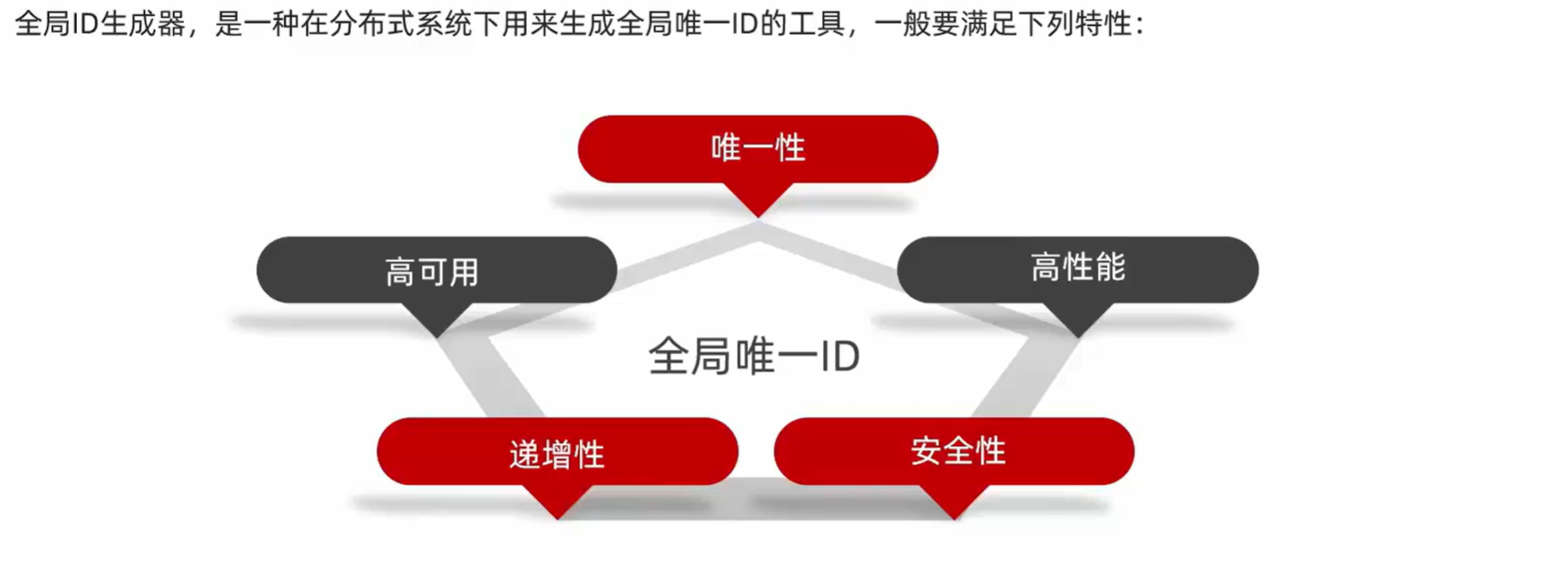
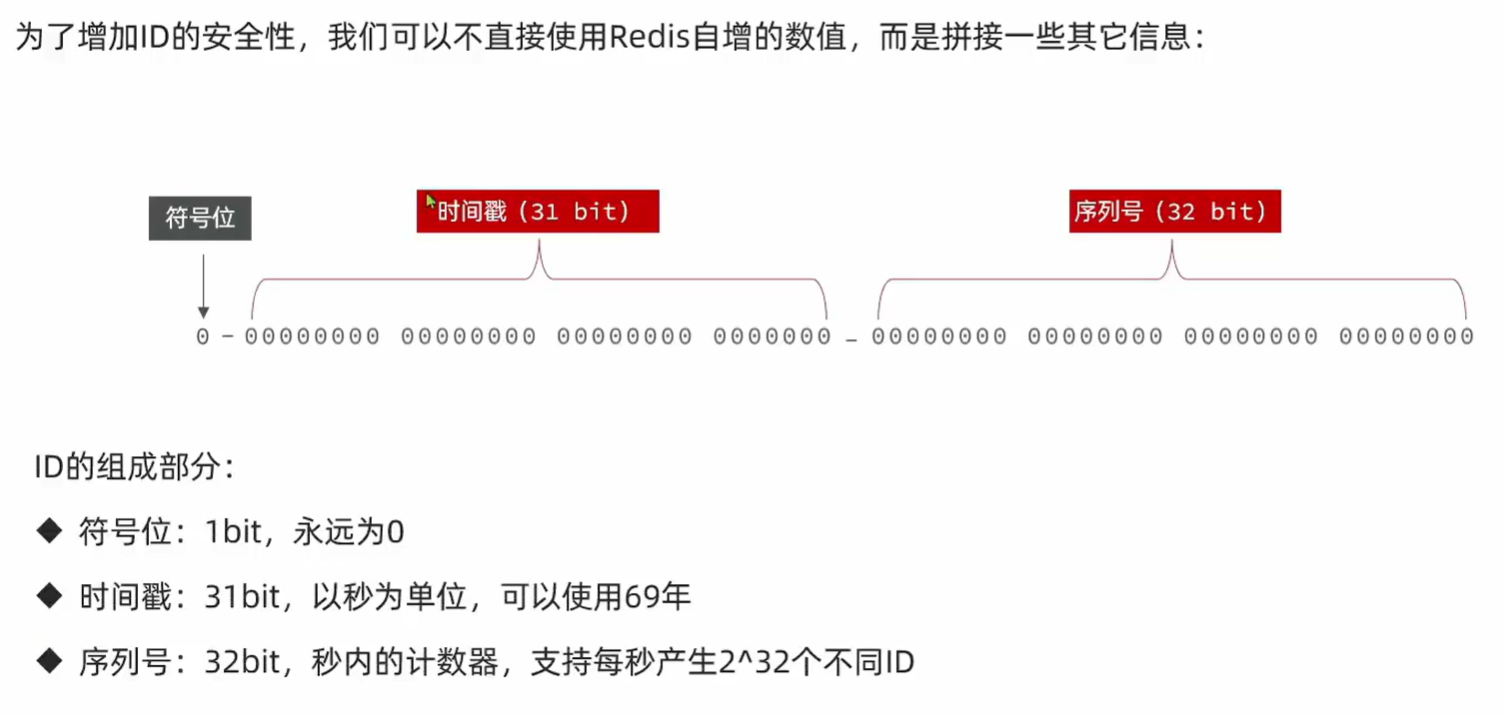
- UUID
- Redis自增
- 每天一个key,方便统计订单量
- ID构造:时间戳 + 计数器
- snowflake算法
- 数据库自增
2、添加优惠券


3、优惠券秒杀下单
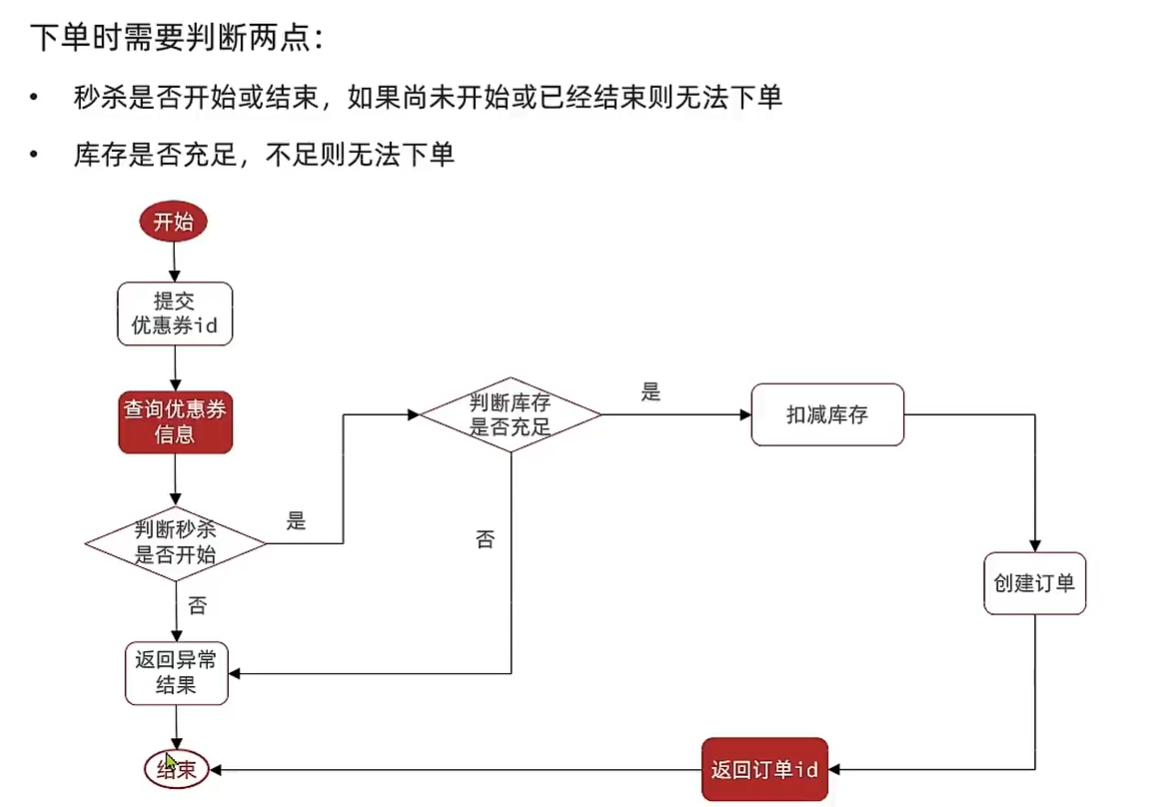
4、超卖问题
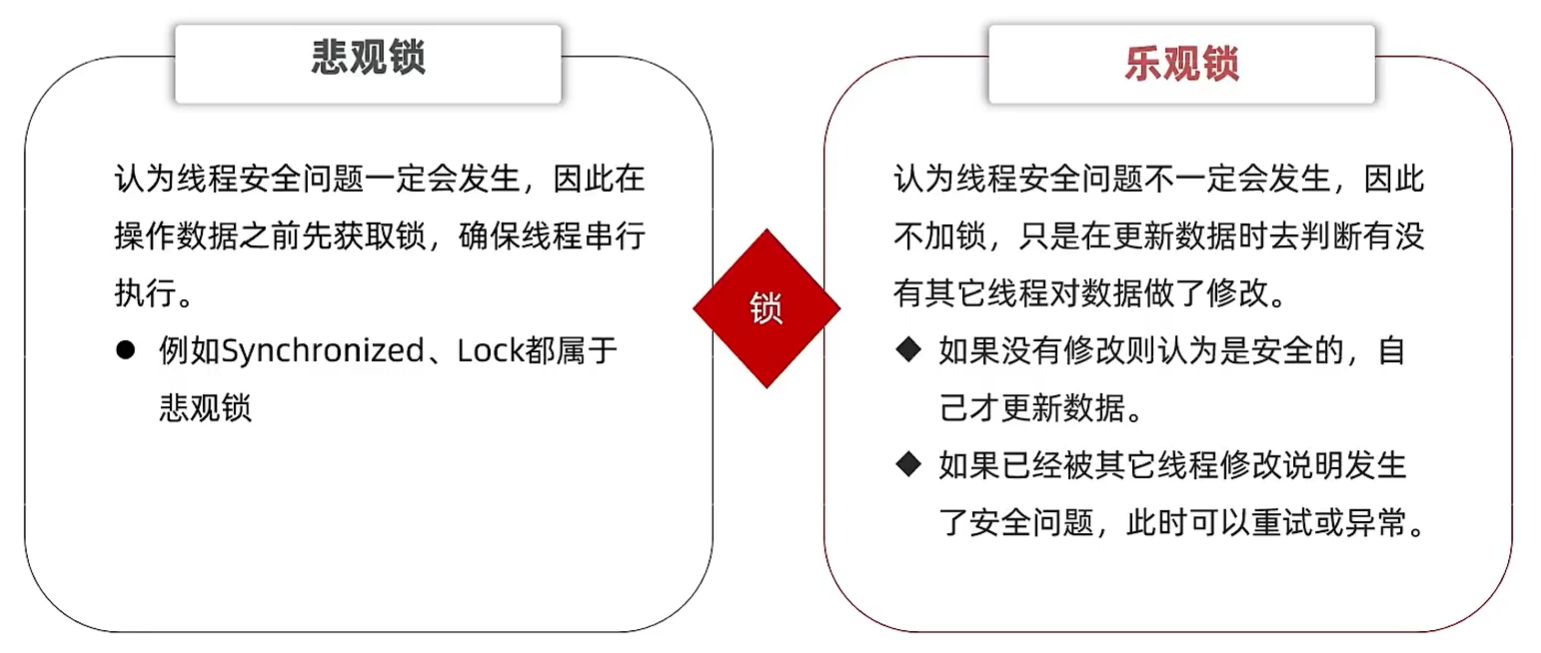
悲观锁
添加同步锁,让线程串行执行
- 优点:简单粗暴
- 缺点:性能一般
乐观锁
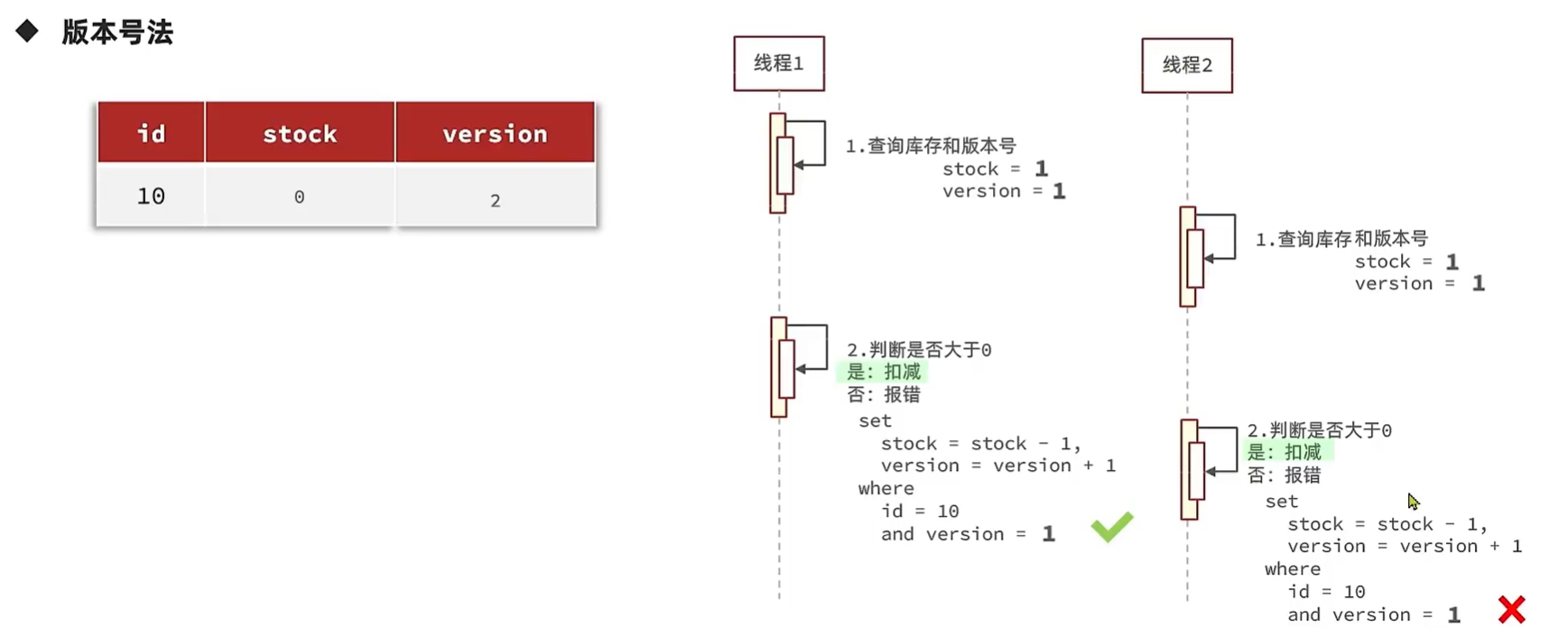
- 版本号法
- CAS法(不需要版本号,直接判断库存是否和之前一样)
这两种是判断库存是否和查询时一模一样的,在高并发的情况下,很容易出现不一样的情况,导致该线程不执行后续内容。但是其实还是可以消费的,因为库存还有很多。
更好的做法不是看库存是否和查询的时候一样,而是看消费之前**库存是否是>**0就可以了。
5、一人一单
上面超卖的问题是可以通过乐观锁来查询 库存 是否改变,再判断是否继续执行(通过SQL中的where来判断,筛选到就修改,筛选不到就不改)。但是这里,是创建数据,无法通过SQL语句来实现 乐观锁 的概念 。
->采用悲观锁。对用户个体加锁。
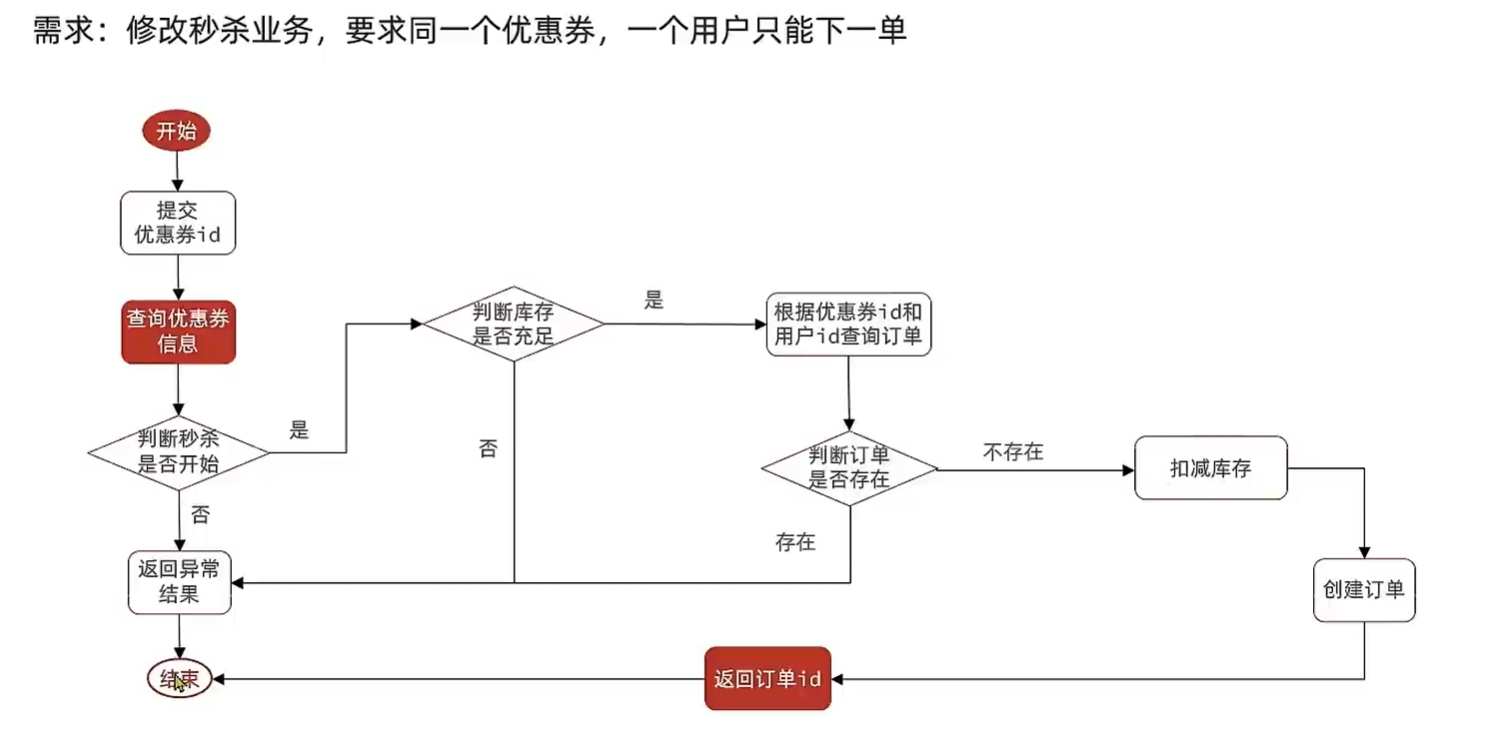

(如果不存在相同的内容,就将其加入常量池,并返回地址。)
存在一个问题
由于这个方法添加了事务,所以是数据库操作先完成,先释放锁,然后方法再执行完毕,返回调用这个方法的位置、提交事务。那么这个时间差内,事务没有提交,别的线程获得锁进来以后,依然存在不一致问题。
又不能锁这个方法(因为要细粒度的锁用户个体)
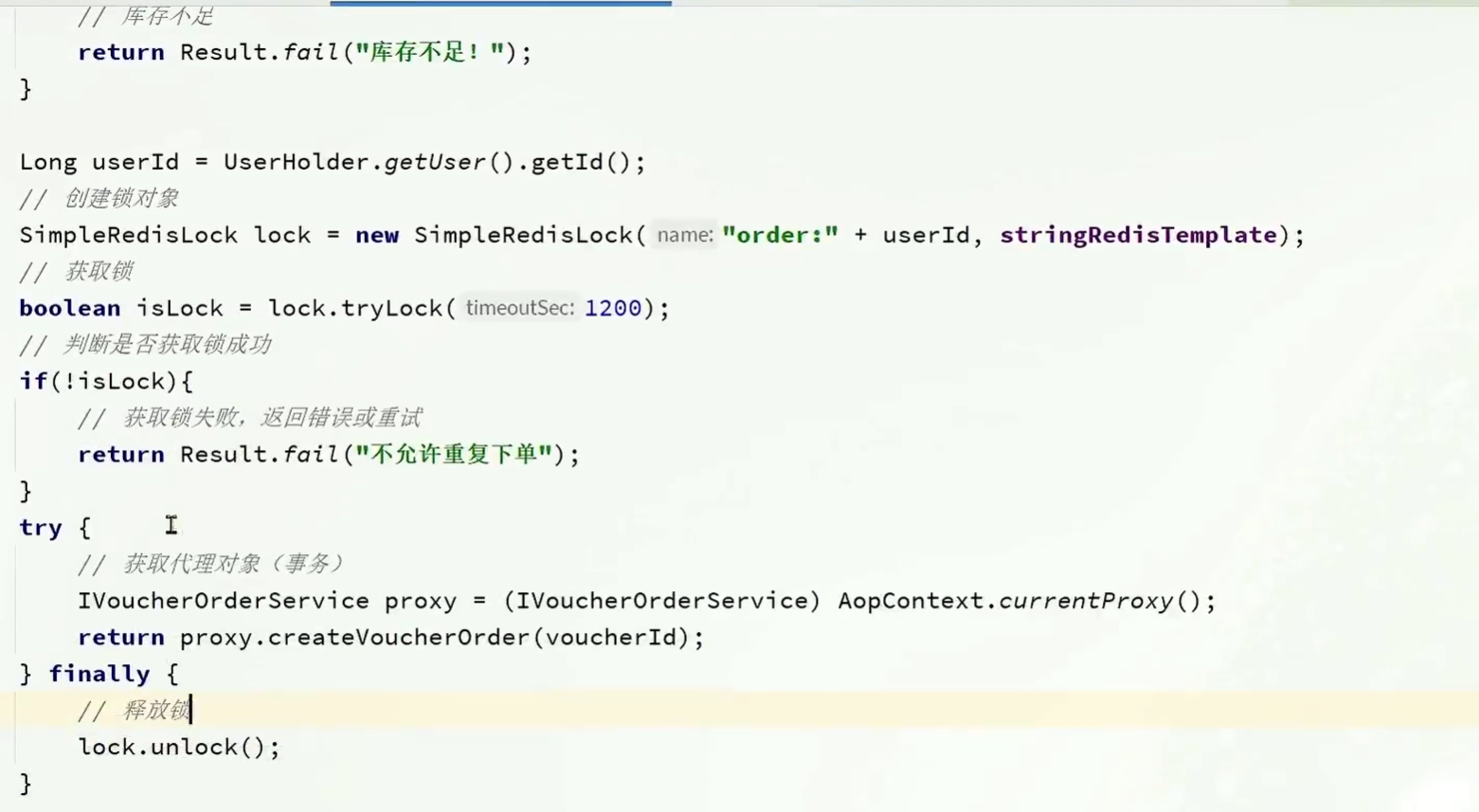
->将锁放在调用这个方法的代码前面。
这样就可以等事务提交完,再释放锁了。
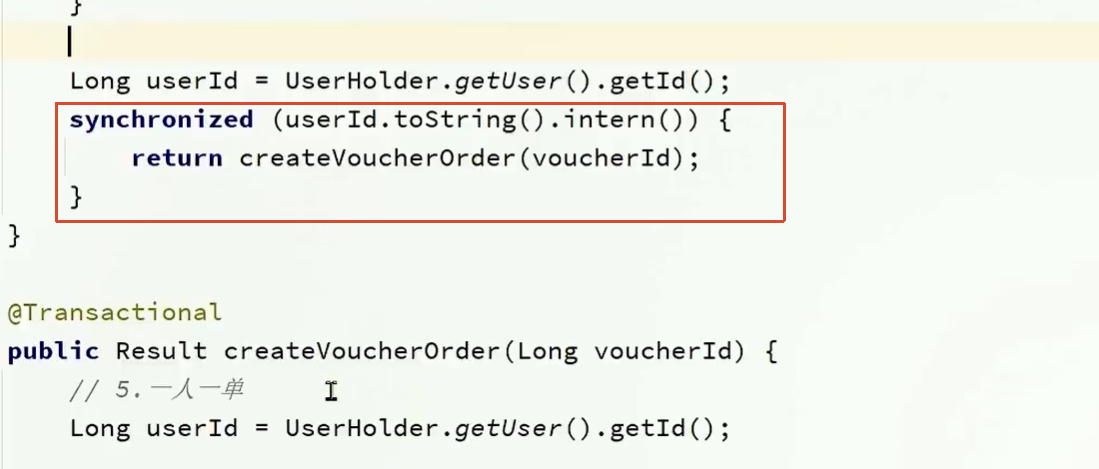
事务失效的问题
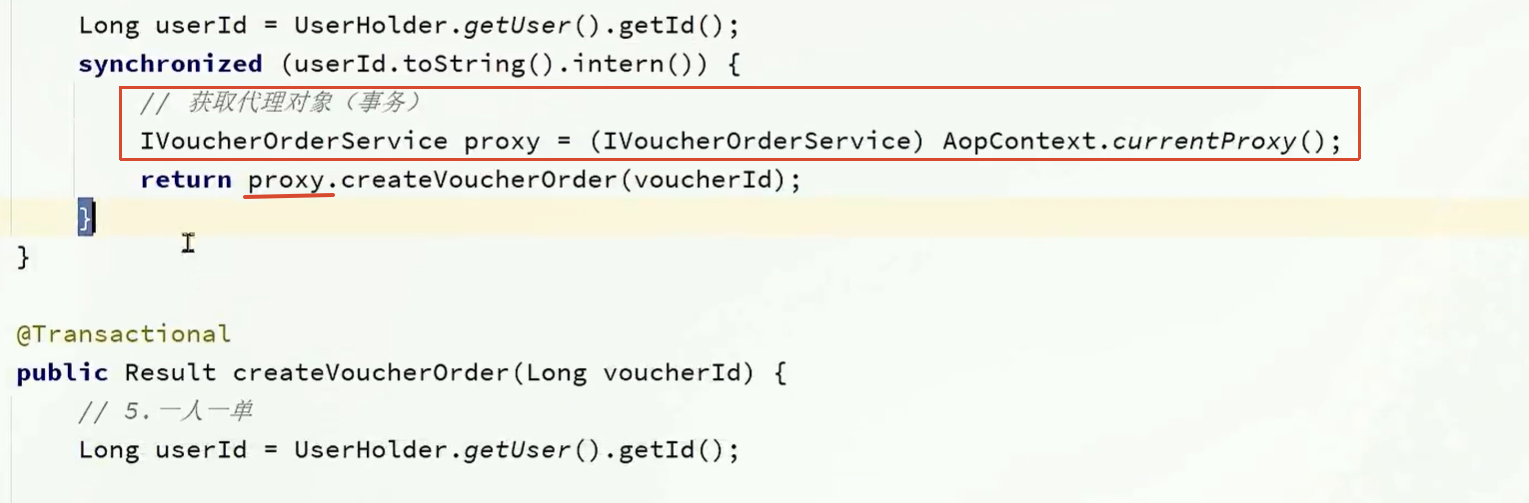
由于这里调用函数是调用自己的函数,也就是this.createVoucherOrder();,这没有经过代理对象,所以无法执行Spring实现的事务。只有代理对象才能实现事务。
所以需要先获取当前对象的代理对象
用AopContext.currentProxy()方法获取当前对象的代理对象。
需要
- 添加Aspectj依赖
- 暴露代理对象(否则无法获取代理对象)
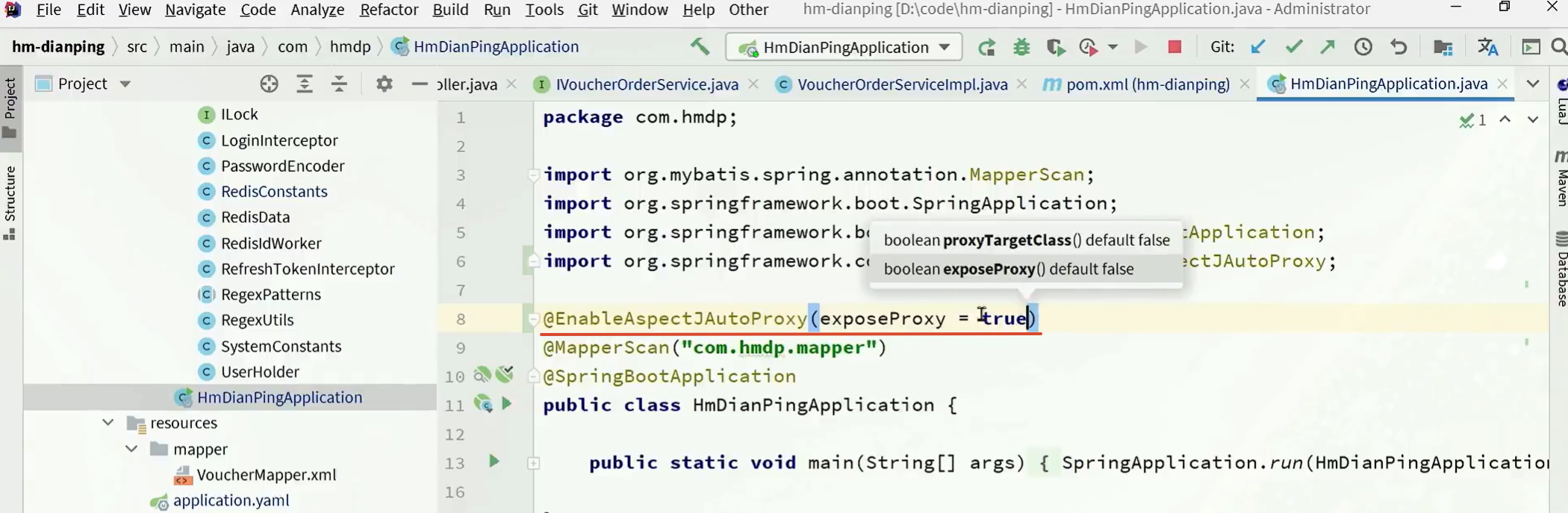
修改后的代码:
5.2 多服务器下产生的问题
虽然前面使用了悲观锁,但是锁的机制是JVM中会有一个锁监视器来判断是否加锁,不同JVM都有自己的堆、栈、方法区等等。在另一个服务器上加锁后,会获得一个全新的锁监视器,两个锁监视器不同,所以可以放进两个线程。导致又出现了并发问题。
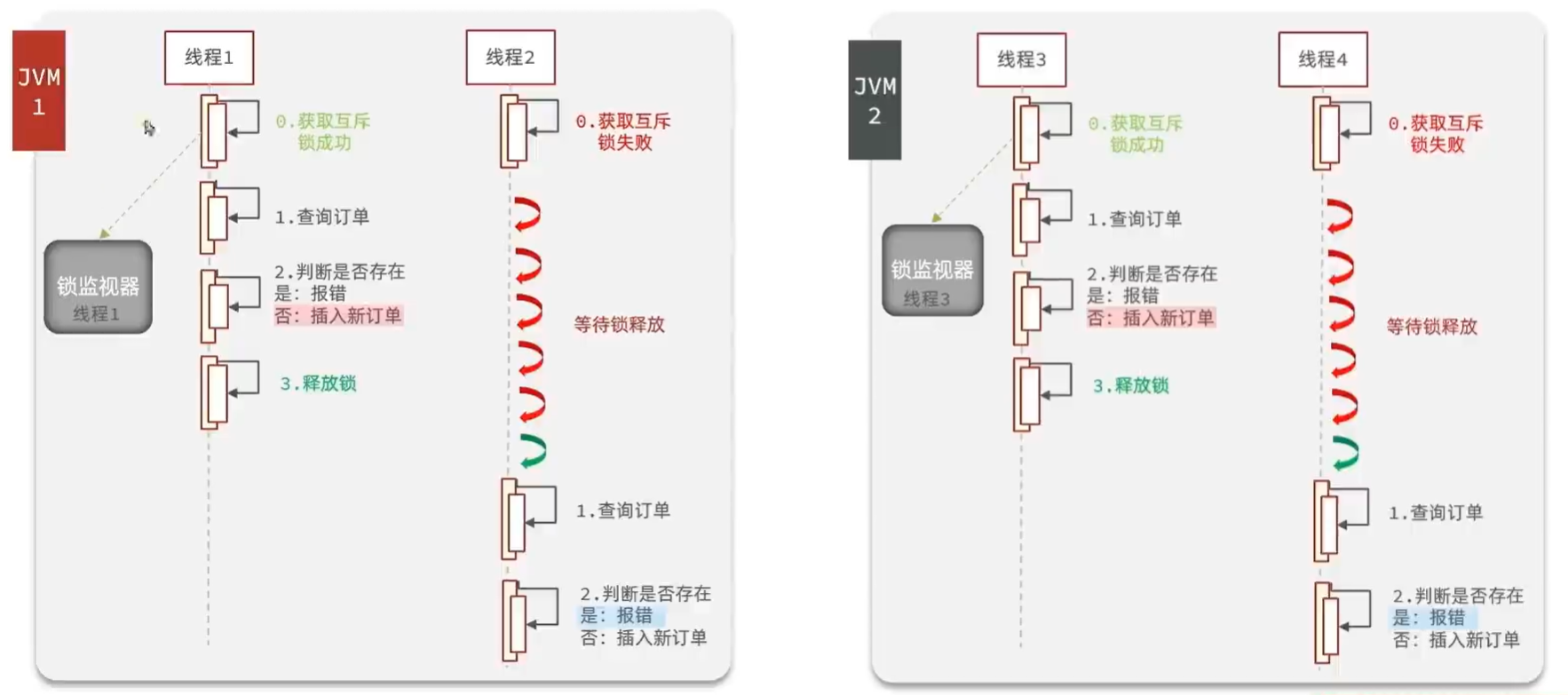
所以,集群中有几个JVM,就会有几个线程并行运行。
那么,如何让多个JVM中使用同一把锁?
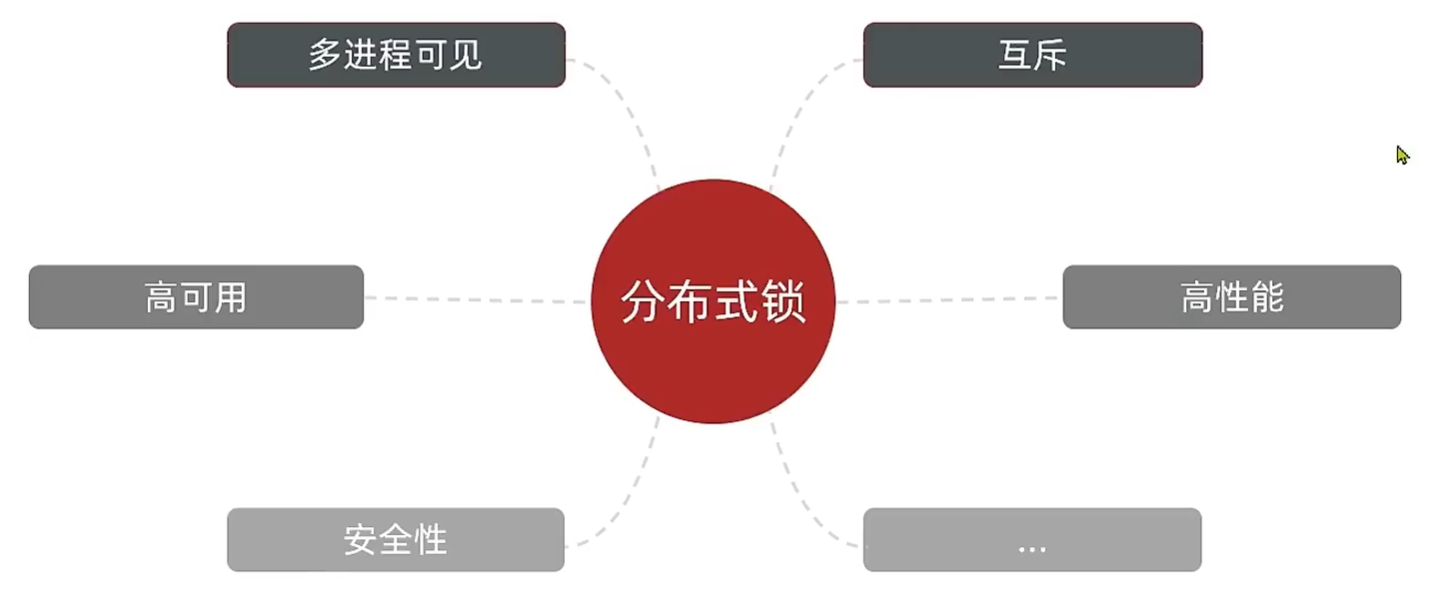
分布式锁
在分布式系统或集群模式下,多进程可见并且互斥的锁。
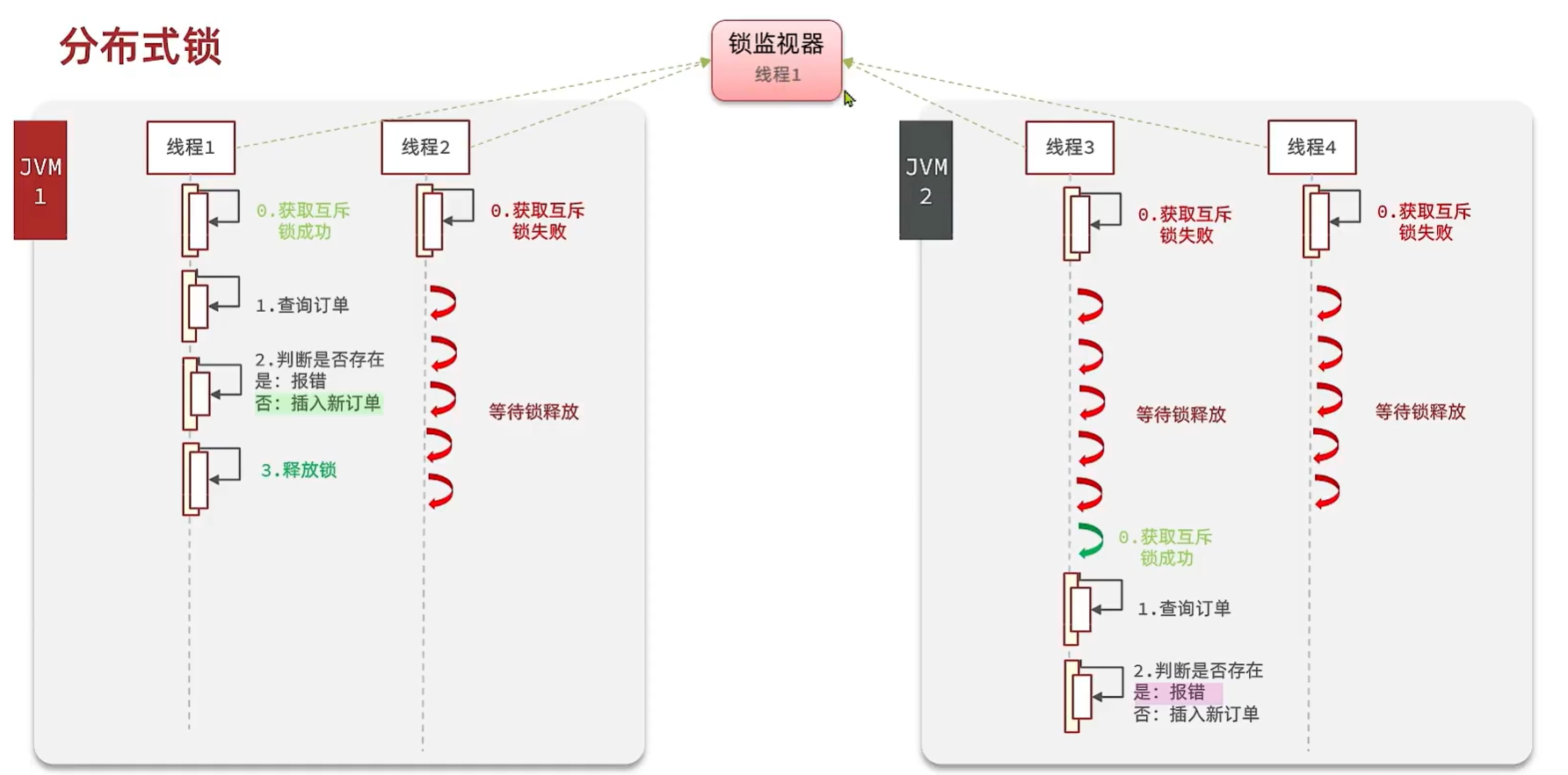
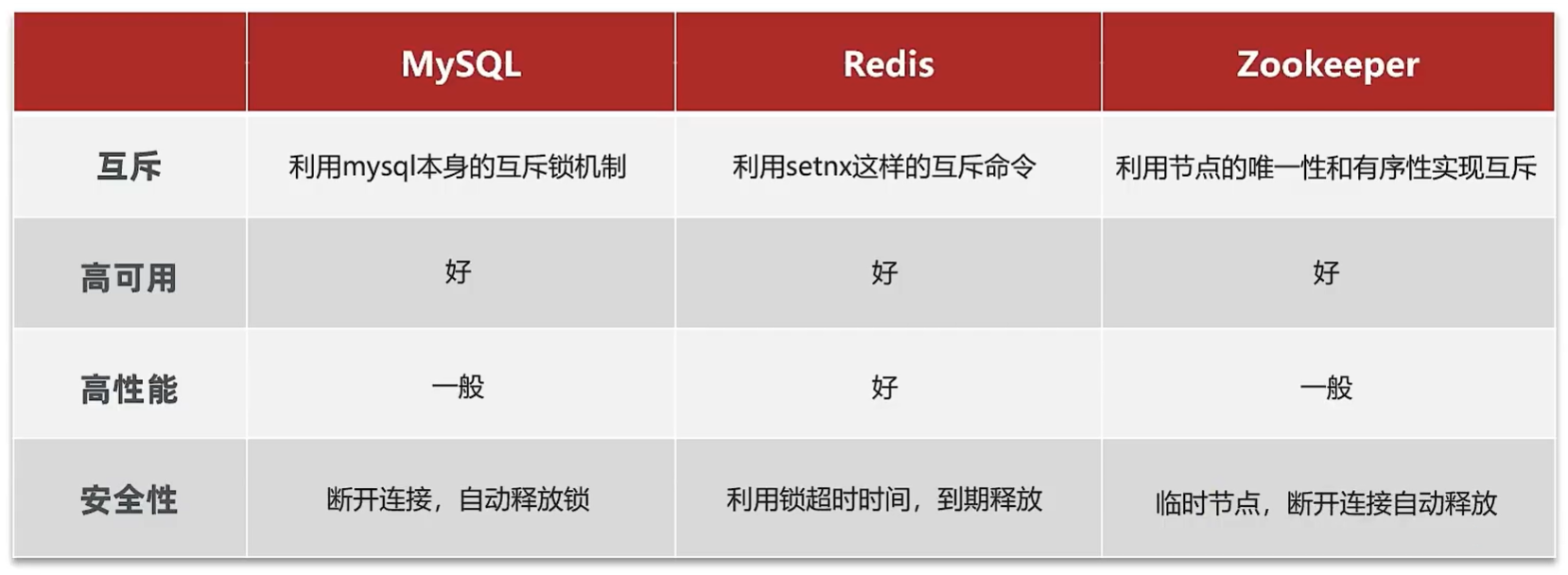
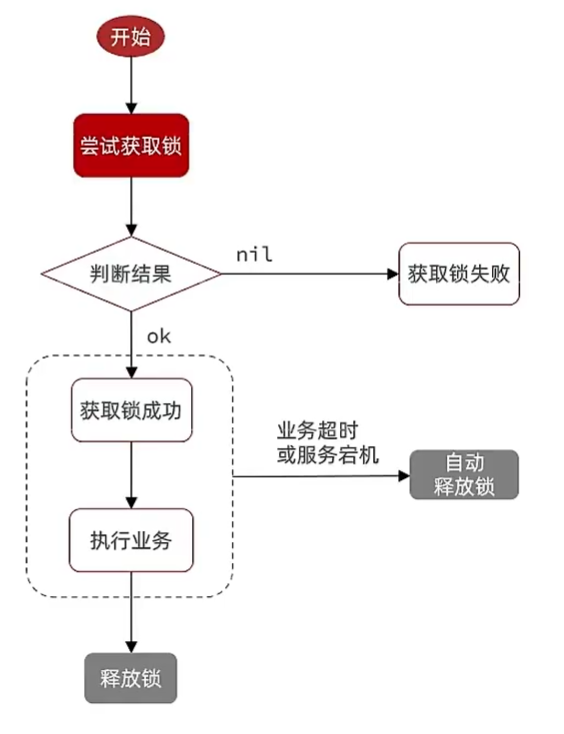
基于Redis的分布式锁

使用SETNX的话,还需要在下面加一个EXPIRE lock 时间防止这个线程因为某些问题没有执行完,没有释放锁,导致别的线程都进不来。
但是,如果在添加锁和设置过期时间中间出问题怎么办?需要原子操作
使用SET语句,可以在一个操作内设置EX,NX等参数
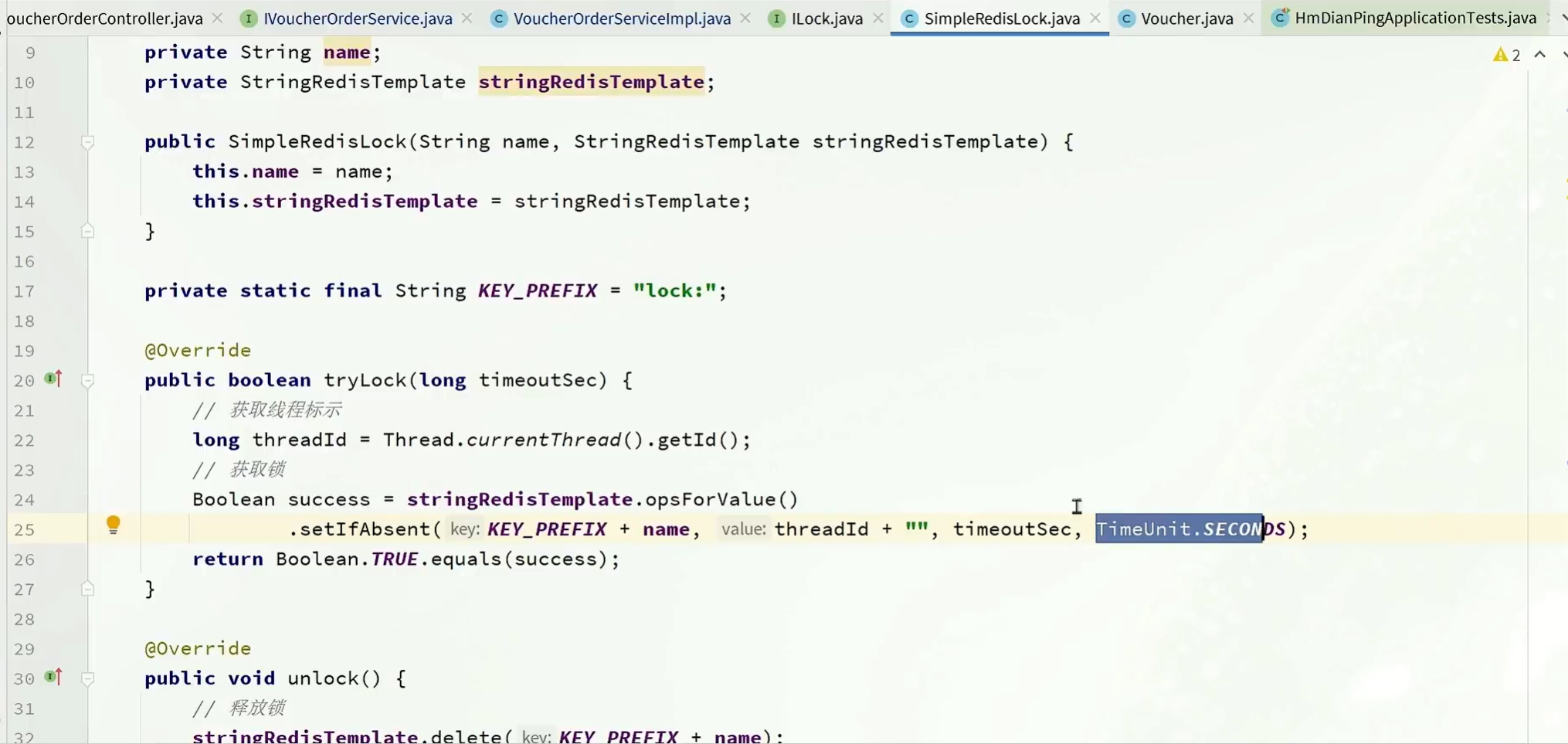
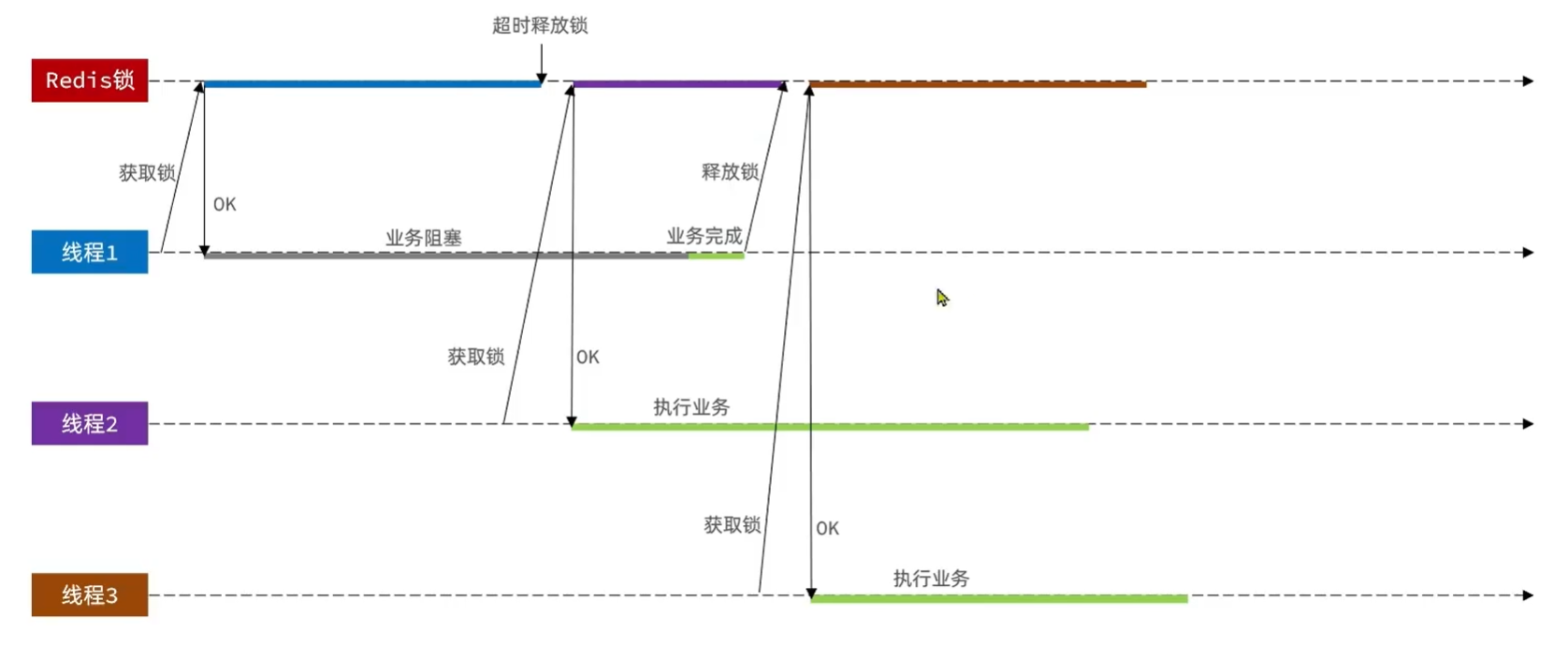
存在的问题
如果拿到锁的线程阻塞了很久,锁已经超时释放了。别的线程就可以获取到这个锁,开始执行任务。然后原来的线程结束后,又把别人的这个锁释放了。完全乱套了。
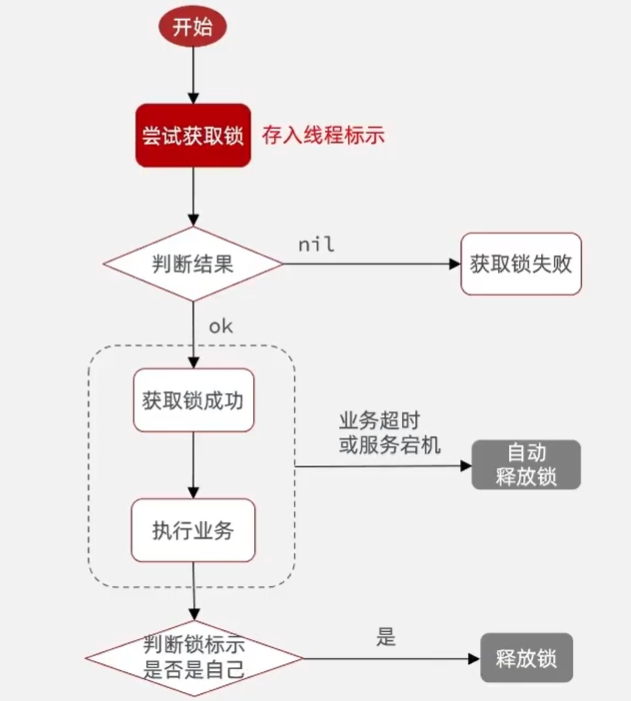
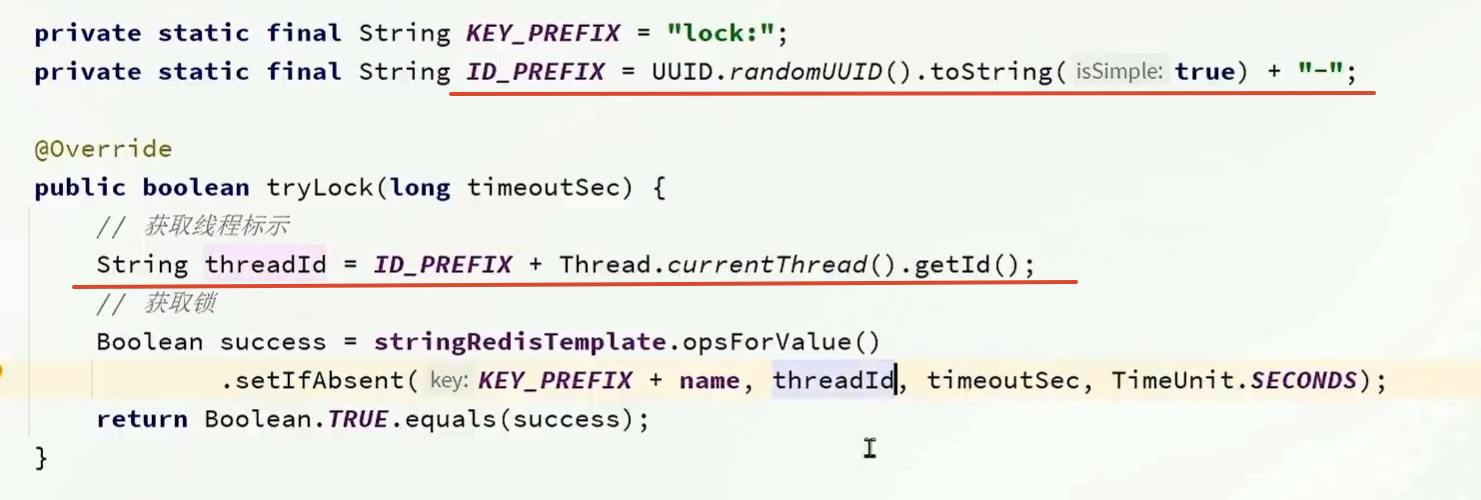
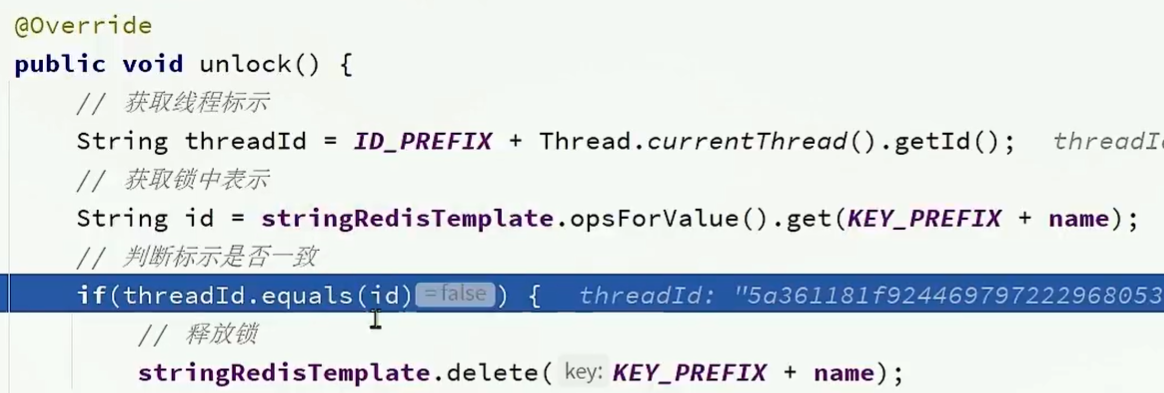
解决误删
在释放锁的时候检查一下锁的value,看看是不是自己的线程id
Redis的原子性
使用Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。


Redission

Redisson是一个在Redis的基础上实现Java驻内存数据网格。它提供了一系列的分布式的Java常用对象、分布式服务(包含各种分布式锁的实现)。

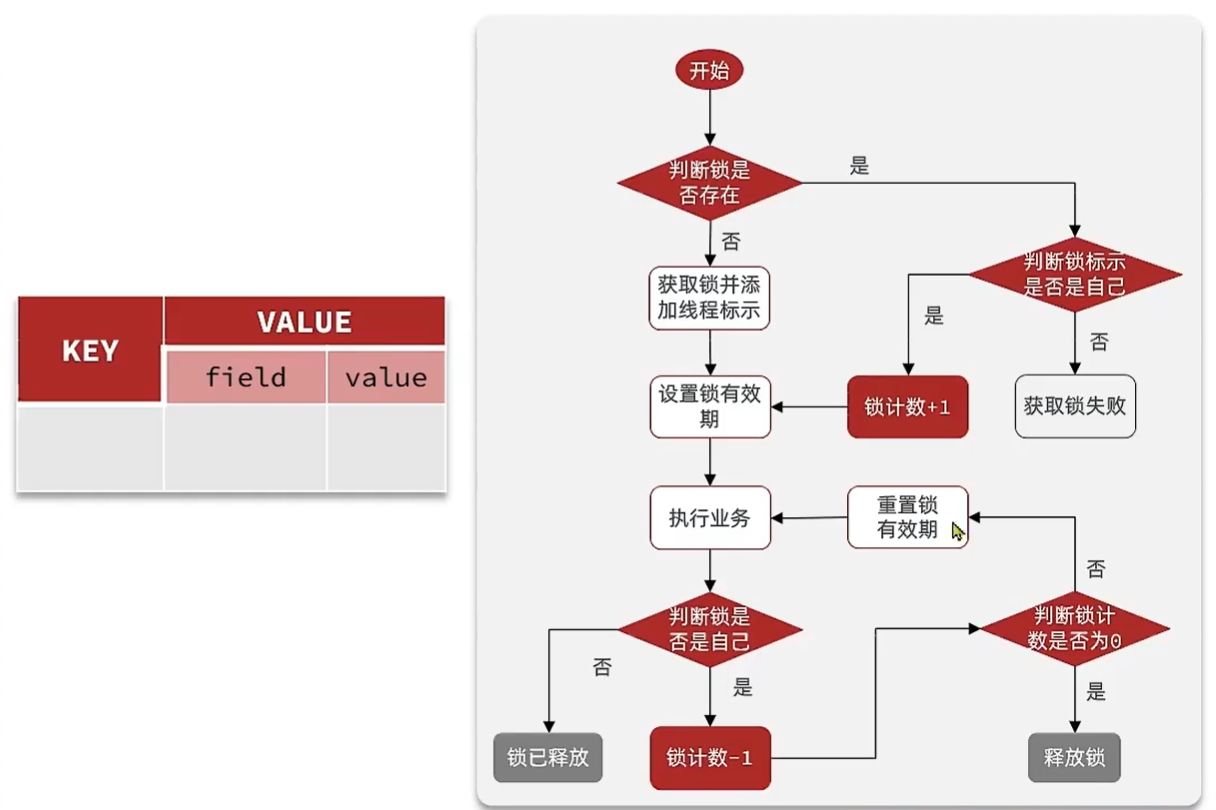
Redission可重入锁原理
利用hash结构记录线程id和重入次数,如果id相同,就可以再次获得锁,重入次数+1
失败重试
利用信号量和PubSub功能实现等待、唤醒,获取锁,如果又失败了就再等待。(有一个等待的时间,超过这个时间了就不再重试)
超时释放
利用watchDog,每隔一段时间(releaseTime/3),重置超时时间。
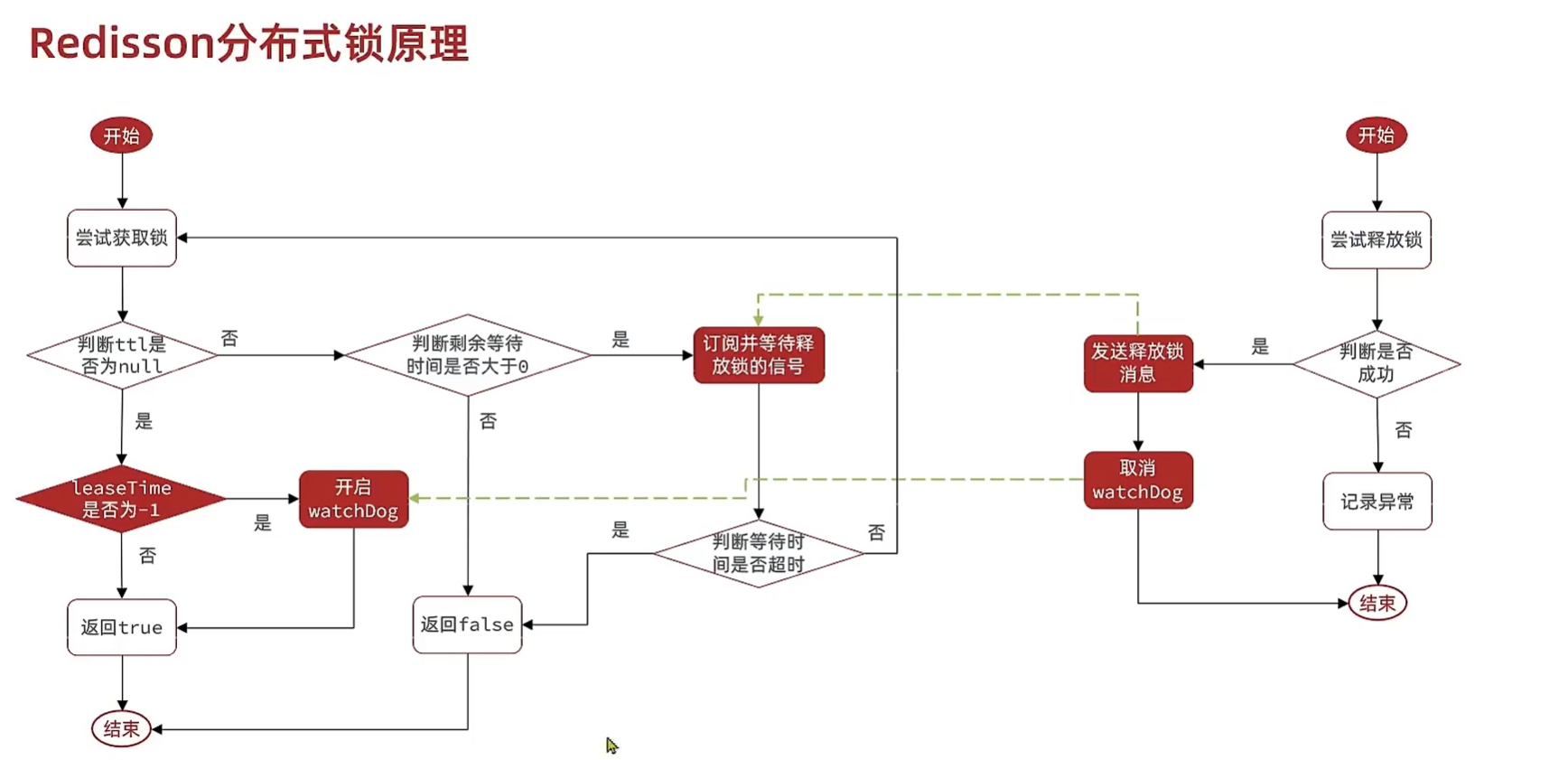
尝试获取锁的时候,如果获取失败,会返回锁还有多久过期;如果获取成功,则返回null
leaseTime是获取锁后自动释放的时间,如果为-1,就是没有设置。那么交给watchDog处理,默认过期时间是30s,每隔30/3=10s就检测一次,如果检测到该线程仍然持有这把锁就把过期时间重新置为30s。
解决主从一致性
主从一致性问题:如果已经获取锁后,主服务器失效,从服务器变成主服务器,但由于没来得及同步,导致从服务器失去锁标识,别的线程也可以获取锁了。
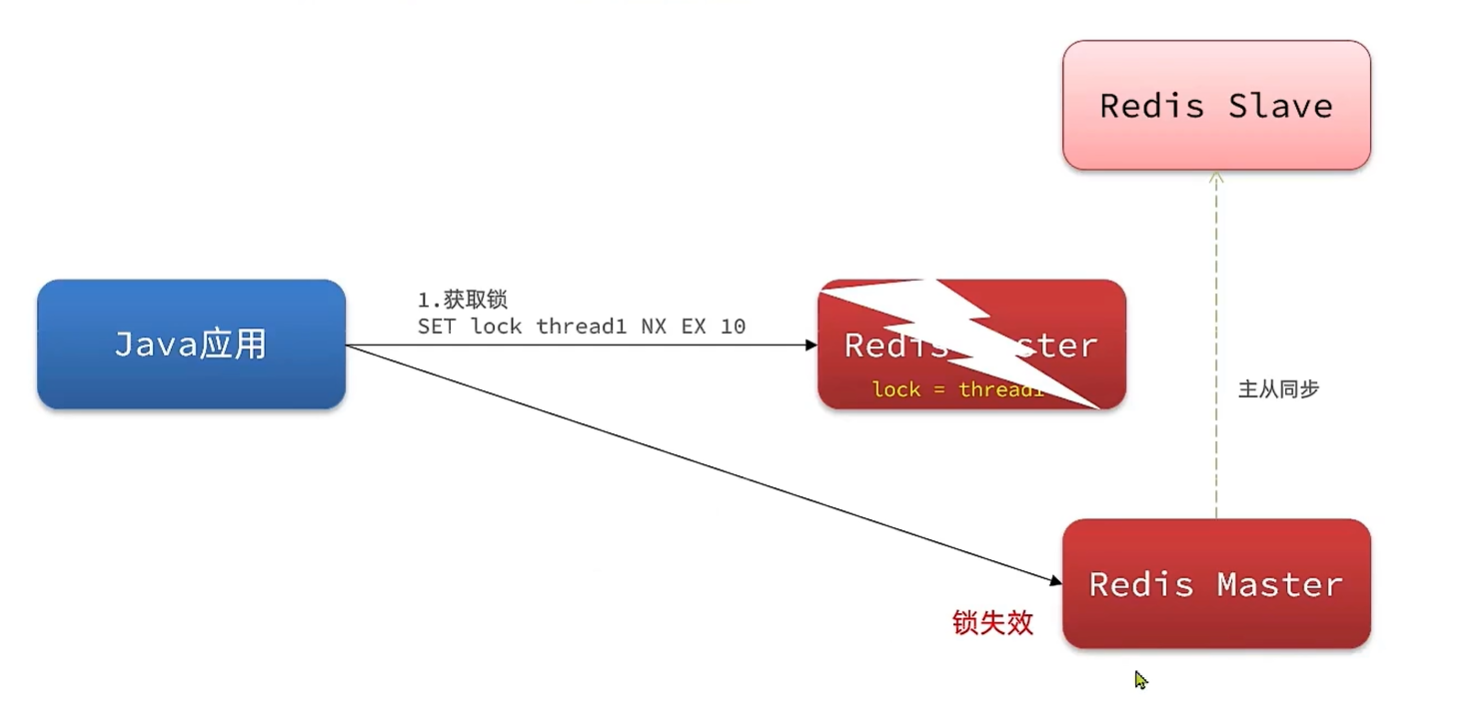
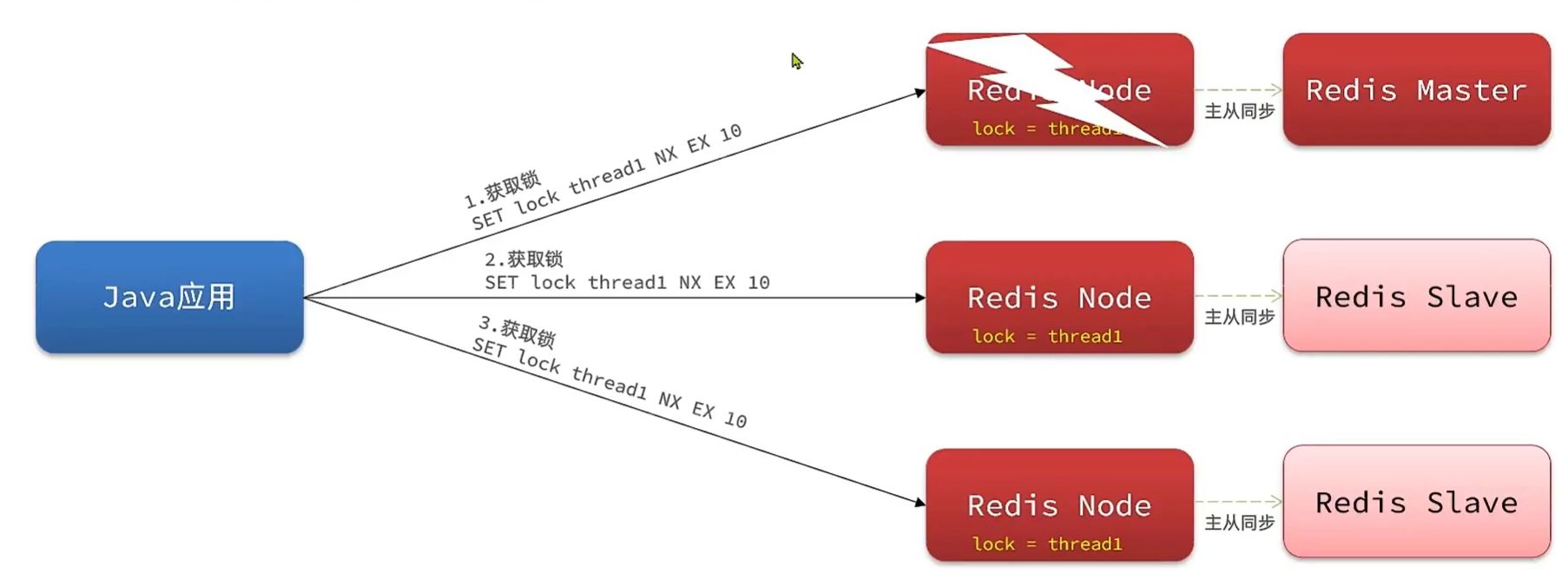
Redission 解决方案
multiLock:Java应用对接的redis服务器不区分主从,需要向所有的服务器获取锁后,才算成功。可以为这些服务器设立从服务器进行主从同步,但不会出现主从一致性问题。
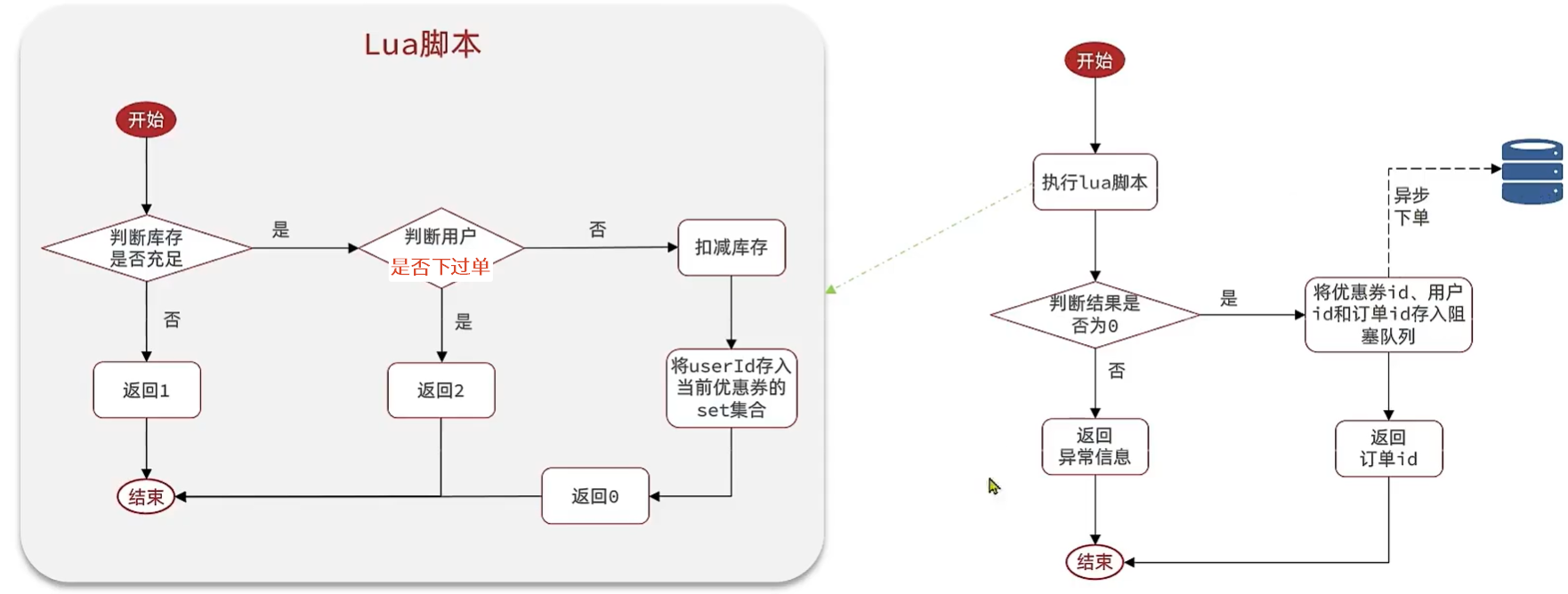
Redis秒杀优化
思路:
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务,记录订单信息
- 将下单业务放入阻塞队列,利用独立线程异步下单
使用set类型来存储下过单的用户

阻塞队列 BlockingQueue
线程在阻塞队列中获取元素时,如果没有元素,这个线程就被阻塞,直到有元素后才会被唤醒
使用ArrayBlockingQueue
存在的问题:
可能同一时间有很多订单放置到阻塞队列中,如果不限制队列长度,可能导致内存占满;如果设置队列长度,剩余的订单后续无法正常创建。
如果服务器突然宕机,会导致数据全部丢失,没有创建订单,但用户已经付款。
内存限制
数据安全
因此,需要使用消息队列来解决以上问题。
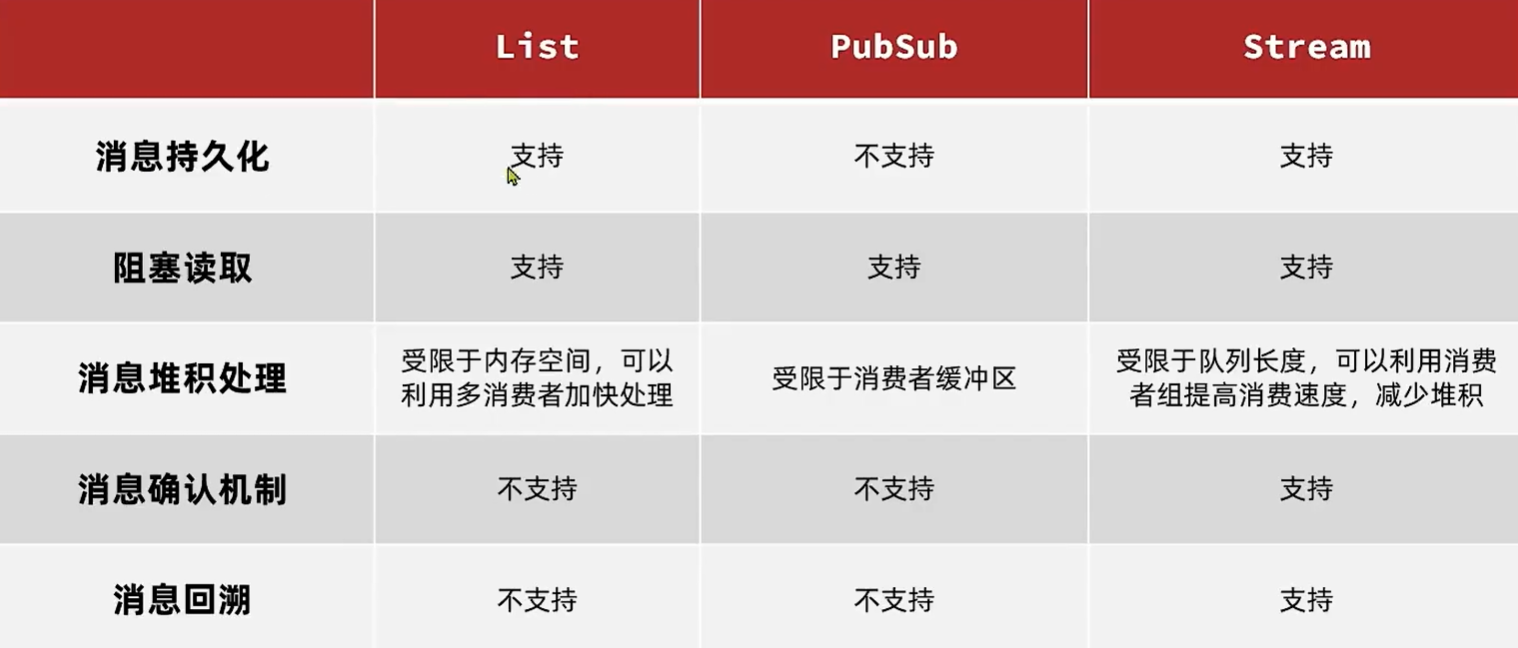
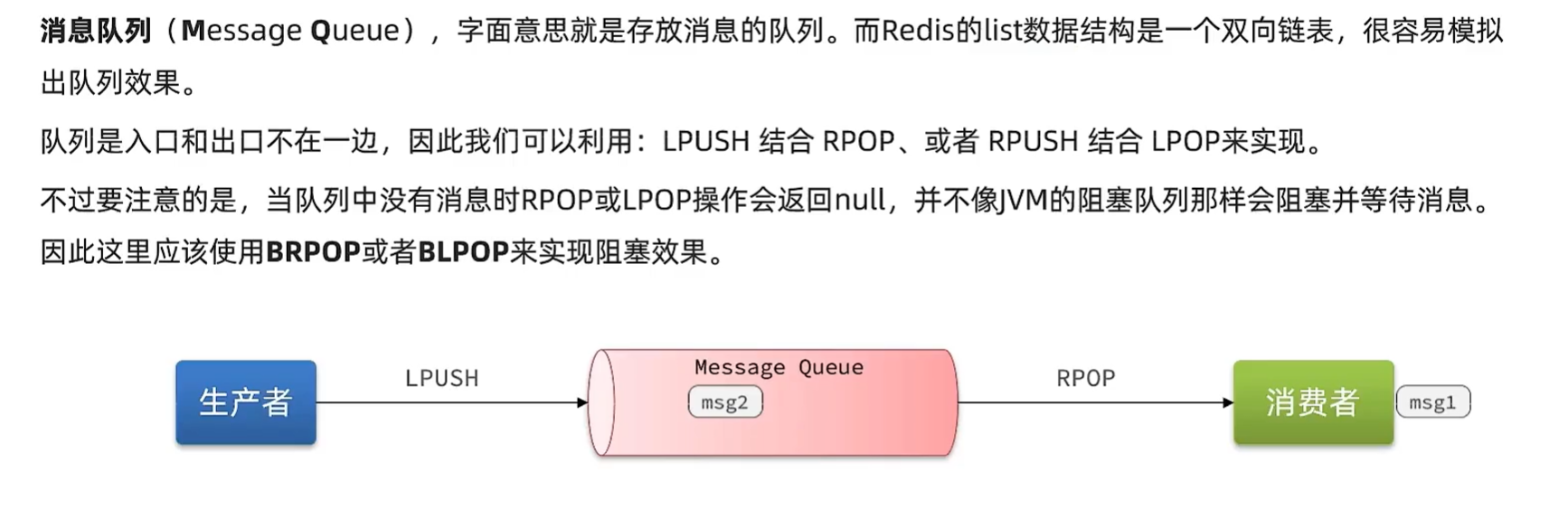
Redis消息队列
基于list的实现方式

基于PubSub的实现方式
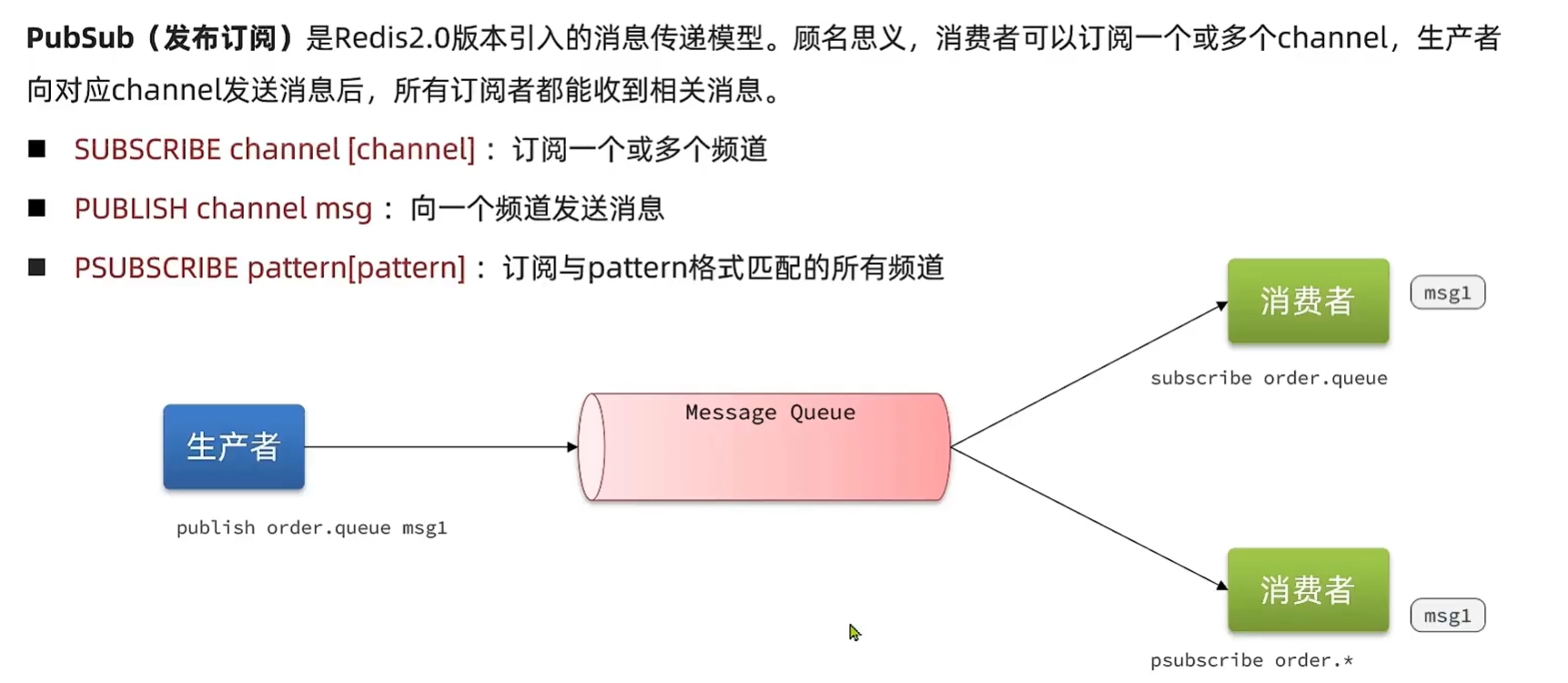

不是数据结构,只是一个通道,没有存储能力。
基于Stream的实现方式
Redis5.0引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息 XADD

最简:

读取消息 XREAD

但是XREAD存在消息漏读的问题:
XREAD BLOCK 0 STREAMS stream.orders $
在它阻塞后,别的线程发送了多条消息(ABC),它只能获取到第一条消息A。此时,再次执行XREAD消息,消息A后面的那些消息BC它都读不到。只有另一个线程再发送一条消息,才能获取这条最新的消息。
因为**$意思是:只读未来新消息,可能跳过已经存在但没读到的消息**
解决办法是每次读的时候使用上一个消息的ID,而不要使用$
消费者组
将多个消费者划分到一个组中,监听同一个队列。


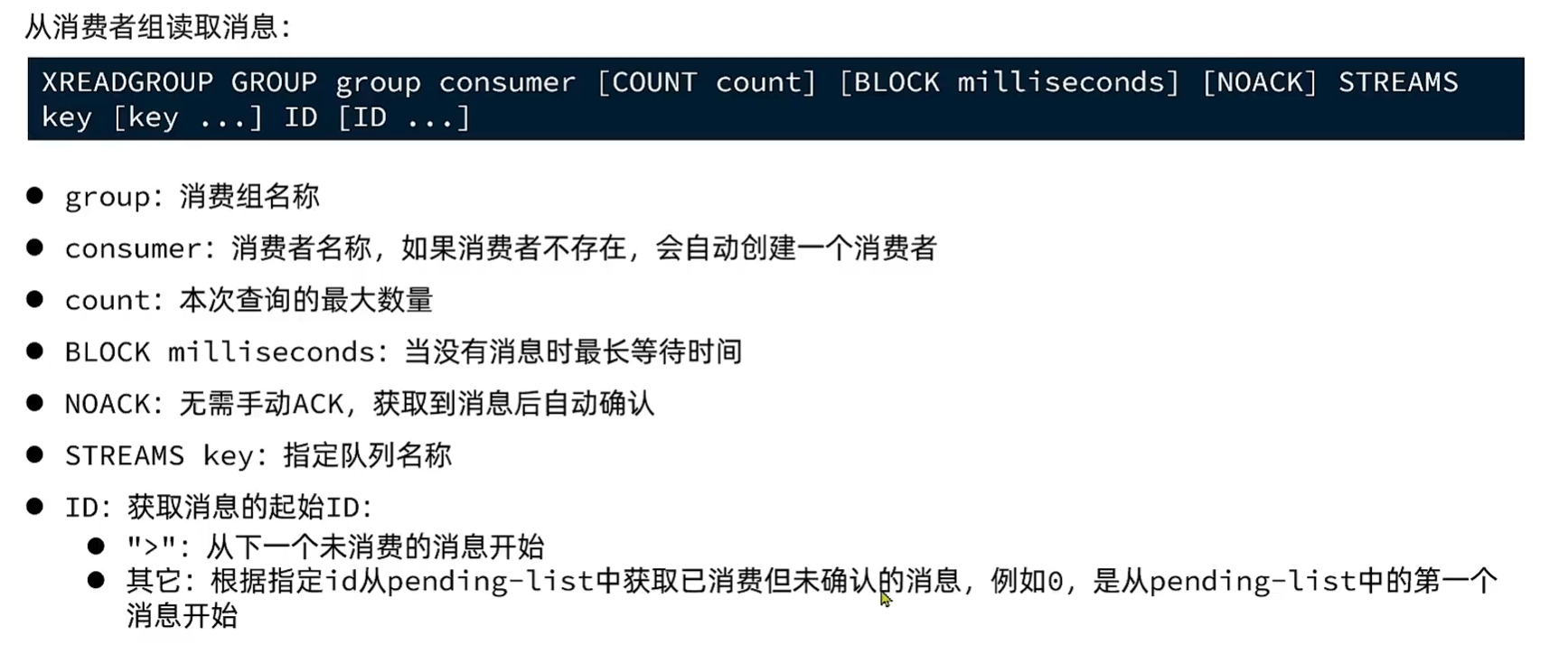
消费者监听伪代码:


总结